不使用Python循环
代码
def get_indexes_darrylg(x, y):
' darrylg answer '
overlap = np.intersect1d(x, y)
loc1 = np.searchsorted(x, overlap)
loc2 = np.searchsorted(y, overlap)
return np.dstack((loc1, loc2))[0]
使用方法
x = np.array([1, 2, 8, 11, 15])
y = np.array([1, 8, 15, 17, 20, 21])
result = get_indexes_darrylg(x, y)
[2, 1],
[4, 2]], dtype=int64)
发布的解决方案的时间
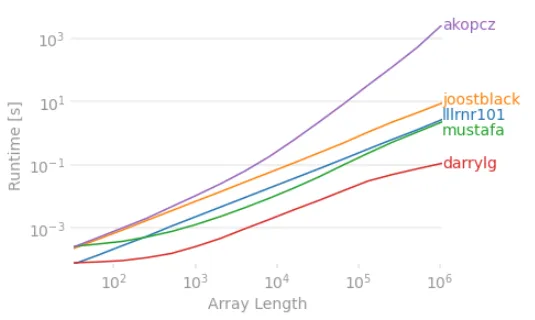
结果显示,darrlg代码具有最快的运行时间。
代码调整
- 将每个发布的解决方案作为一个函数。
- 轻微修改,使每个解决方案输出一个numpy数组。
- 曲线以发布者命名
代码
import numpy as np
import perfplot
def create_arr(n):
' Creates pair of 1d numpy arrays with half the elements equal '
max_val = 100000
arr1 = np.random.randint(0, max_val, (n,))
arr2 = arr1.copy()
all_indexes = np.arange(0, n, dtype=int)
indexes = np.random.choice(all_indexes, size = n//2, replace = False)
np.put(arr2, indexes, np.random.randint(0, max_val, (n//2, )))
arr1 = np.sort(arr1)
arr2 = np.sort(arr2)
return (arr1, arr2)
def get_indexes_lllrnr101(x,y):
' lllrnr101 answer '
ans = []
i=0
j=0
while (i<len(x) and j<len(y)):
if x[i] == y[j]:
ans.append([i,j])
i += 1
j += 1
elif (x[i]<y[j]):
i += 1
else:
j += 1
return np.array(ans)
def get_indexes_joostblack(x, y):
'joostblack'
indexes = []
for idx,val in enumerate(x):
idy = np.searchsorted(y,val)
try:
if y[idy]==val:
indexes.append([idx,idy])
except IndexError:
continue
return np.array(indexes)
def get_indexes_mustafa(x, y):
indices_in_x = np.flatnonzero(np.isin(x, y))
indices_in_y = np.flatnonzero(np.isin(y, x[indices_in_x]))
return np.array(list(zip(indices_in_x, indices_in_y)))
def get_indexes_darrylg(x, y):
' darrylg answer '
overlap = np.intersect1d(x, y)
loc1 = np.searchsorted(x, overlap)
loc2 = np.searchsorted(y, overlap)
return np.dstack((loc1, loc2))[0]
def get_indexes_akopcz(x, y):
' akopcz answer '
return np.array([
[i, j]
for i, nr in enumerate(x)
for j in np.where(nr == y)[0]
])
perfplot.show(
setup = create_arr,
kernels=[
lambda a: get_indexes_lllrnr101(*a),
lambda a: get_indexes_joostblack(*a),
lambda a: get_indexes_mustafa(*a),
lambda a: get_indexes_darrylg(*a),
lambda a: get_indexes_akopcz(*a),
],
labels=["lllrnr101", "joostblack", "mustafa", "darrylg", "akopcz"],
n_range=[2 ** k for k in range(5, 21)],
xlabel="Array Length",
equality_check=None,
)