我对读取Excel文件后的数据框进行了操作。我的代码如下:
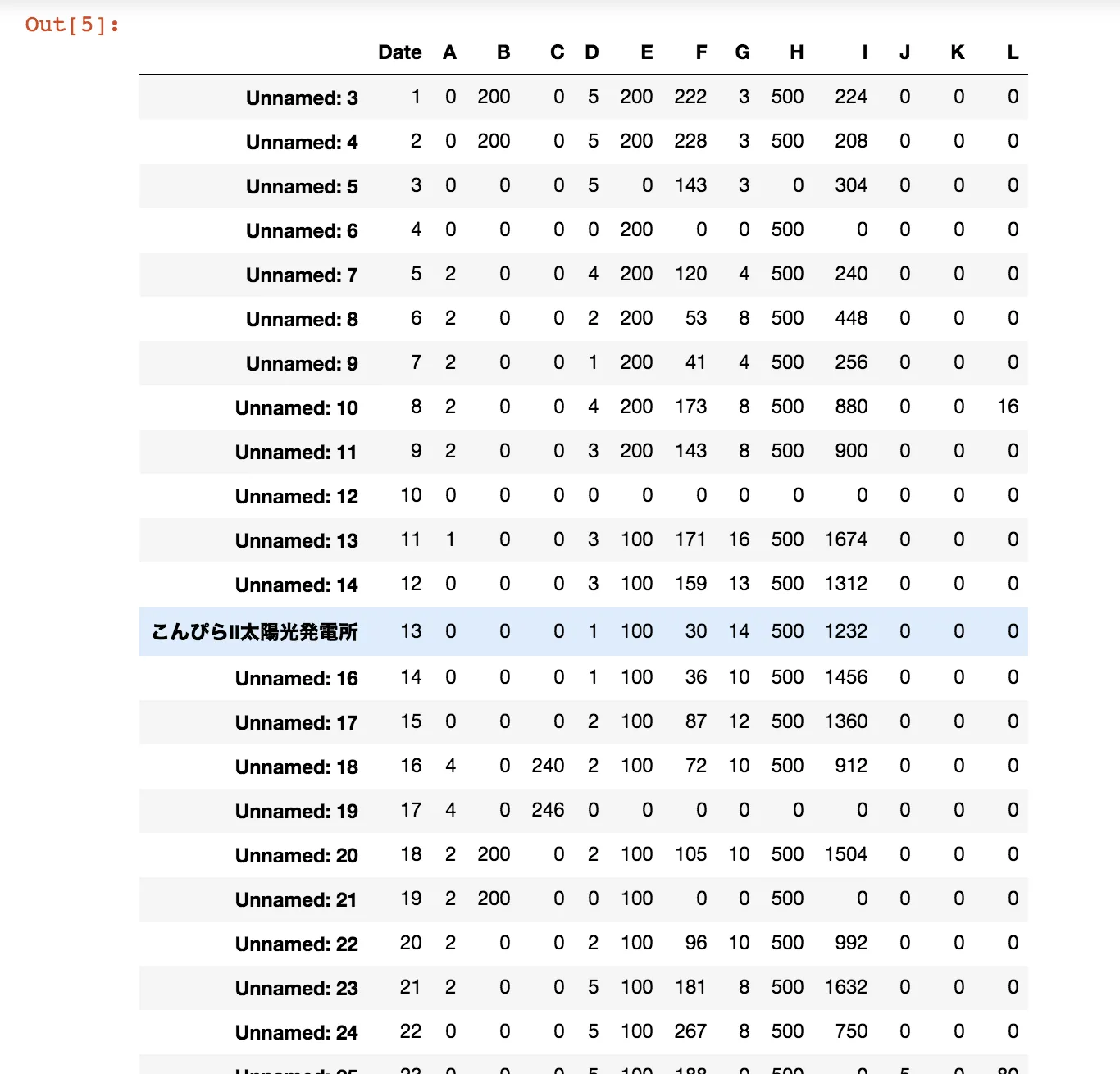
我的输出结果是这样的:点击此处查看图片描述 我想把索引从2019/03/01改为日期范围,但是当我使用以下函数进行更改时:
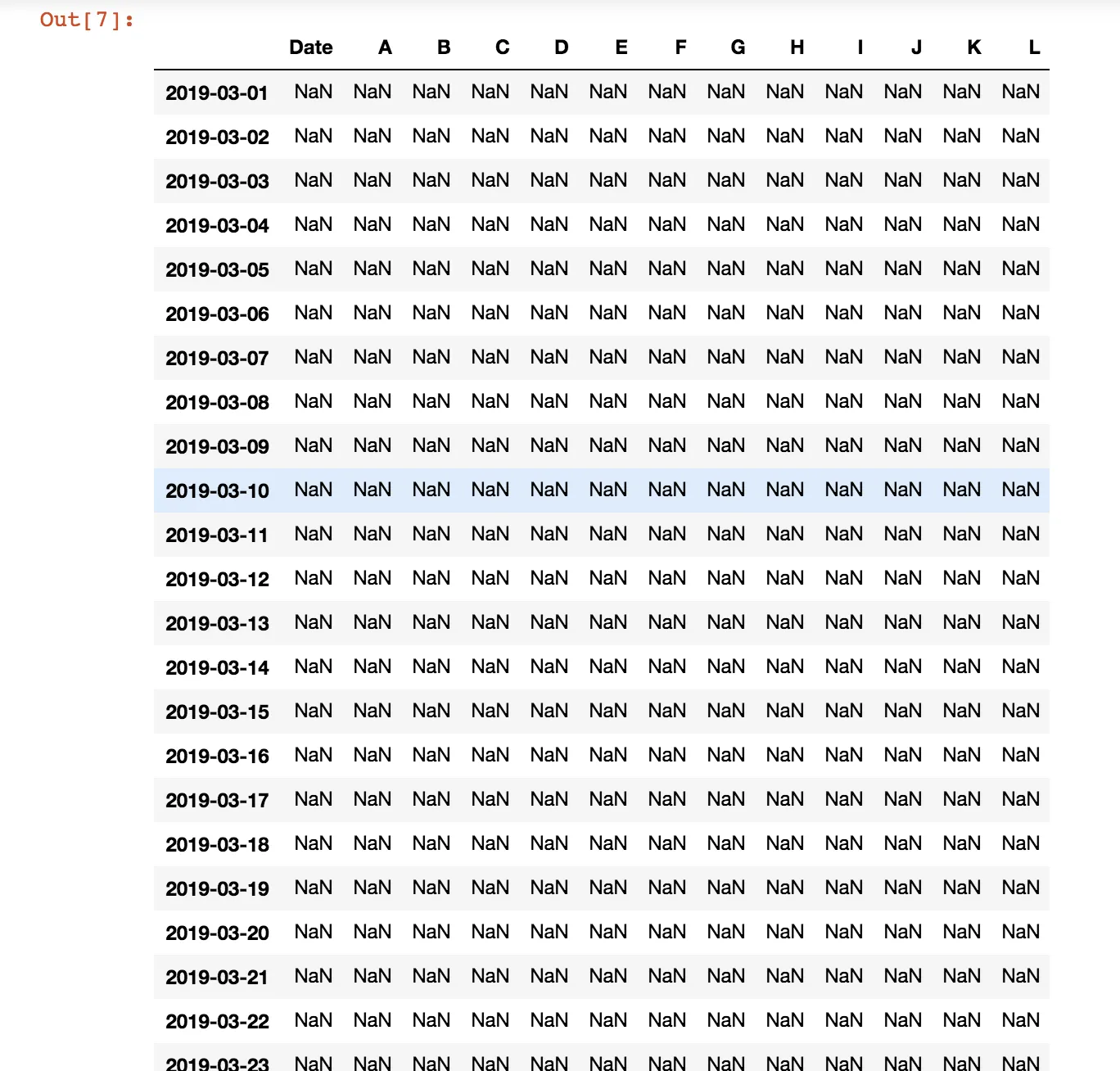
我得到了这个输出: 所有的值都变成了 NaN 。 我刚开始接触 pandas 和数据框架。 在这里输入图片描述 如果我使用多个 Excel 表格,它只适用于一个表格,否则会出错。
import pandas as pd
sheetname = "3月"
required_cols = list(range(3,34))
df1 = pd.read_excel('./weather_data/konpira_plan.xls',
sheet_name=sheetname,usecols=required_cols,inplace=True)
rows=[2,4,5,6,9,10,11,14,15,16,19,20,21]
df=df1.loc[rows].T
cols=['Date','A','B','C','D','E','F','G','H','I','J','K','L']
df.columns = cols
df.fillna(0,inplace=True)
df
我的输出结果是这样的:点击此处查看图片描述 我想把索引从2019/03/01改为日期范围,但是当我使用以下函数进行更改时:
{kind=link}
date_index = pd.date_range('2019/03/01', periods=31,freq='D')
df2=df.reindex(date_index)
我得到了这个输出: 所有的值都变成了 NaN 。 我刚开始接触 pandas 和数据框架。 在这里输入图片描述 如果我使用多个 Excel 表格,它只适用于一个表格,否则会出错。
{kind=link}
AttributeError: 'collections.OrderedDict' object has no attribute 'loc'
在这一点上:
df_w=df1.loc[rows].T
pd.read_excel没有指定表名读取 Excel 文件,则输出将是一个包含每个工作表 DataFrame 的字典。您可以使用for sheet_name, df1 in your_dictionary_name.items():迭代字典。 - Shijith