我希望在我的网站中使用Unicode文本。我在数据库中使用nvarchar(max)数据类型来存储数据。当我将Unicode文本保存到数据库中时,一切正常。但是,当我尝试执行某些SQL操作时,Unicode文本就会变成“?????”。 例如,下面的查询:
declare @unicodetext nvarchar(250)
set @unicodetext='बन्द'
select @unicodetext
结果
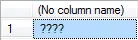
这个问题有什么解决方案吗? 谢谢。
我希望在我的网站中使用Unicode文本。我在数据库中使用nvarchar(max)数据类型来存储数据。当我将Unicode文本保存到数据库中时,一切正常。但是,当我尝试执行某些SQL操作时,Unicode文本就会变成“?????”。 例如,下面的查询:
declare @unicodetext nvarchar(250)
set @unicodetext='बन्द'
select @unicodetext
结果
这个问题有什么解决方案吗? 谢谢。
尝试一下
declare @unicodetext nvarchar(250)
set @unicodetext = N'बन्द'
select @unicodetext
你可能已经注意到,当 SQL Server 为你生成 DDL 脚本时,它会将任何带引号的字符串输入都使用 N。
N修饰符来标识。 - Oded您需要将数据库排序规则设置为接受此类型字符的排序规则,或者您可以像这样在选择语句中添加排序规则子句(谷歌告诉我这是印地语字符)。
declare @unicodetext nvarchar(250)
set @unicodetext='बन्द'
select @unicodetext
COLLATE Indic_General_90_CI_AS