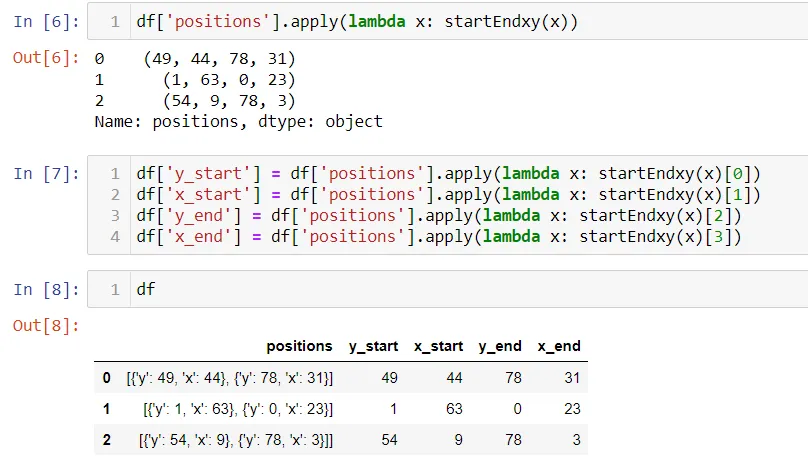
我有一个名为positions的pandas DataFrame列,其中包含以下示例语法的字符串值:
[{'y': 49, 'x': 44}, {'y': 78, 'x': 31}]
[{'y': 1, 'x': 63}, {'y': 0, 'x': 23}]
[{'y': 54, 'x': 9}, {'y': 78, 'x': 3}]
我想在pandas DataFrame中创建四个新列,
y_start、x_start、y_end、x_end,这些列只提取数字。例如,对于第一行示例,我的新列将具有以下值:
y_start = 49x_start = 44y_end = 78x_end = 31总之,我希望提取数字的第一个、第二个、第三个和第四个出现,并将它们保存到各个列中。
{kind=link}