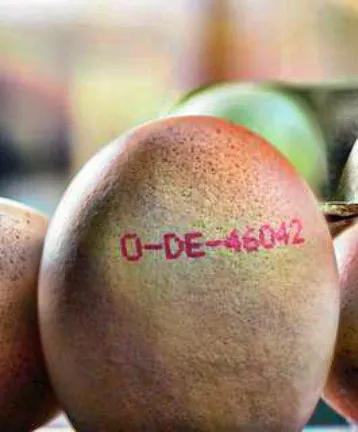目标是创建一个可以识别蛋印记的应用程序,例如
 0-DE-46042
0-DE-46042
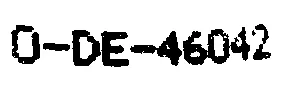

0-DE-134461。我尝试了Tesseract和Google Vision API OCR引擎对以下图像进行识别。两种OCR引擎的结果都很糟糕。
0-DE-46042
Tesseract → ""
Google Vision API → " 2 "
3-ES08234-25591
Tesseract → ""
Google Vision API → " Es1234-2SS ) R SHAH That is part "
裁剪
我使用Photoshop手动裁剪了这些图片。


0-DE-46042
Tesseract → ""
Google Vision API → ""
3-ES08234-25591
Tesseract → "3ΓÇöE503ΓÇÿ234-gg"
Google Vision API → " -ESOT23-2559 ) "
阈值化
我使用Photoshop手动选择了两个鸡蛋上的文本并去除了背景。
0-DE-46042
Tesseract → "OΓÇöDEΓÇö46042"
Google Vision API → " O-DE-46042 "
3-ES08234-25591
Tesseract → ""
Google Vision API → " 3-ESO8234-9 "
如何消除圆形变形?
我认为最后的预处理步骤应该是消除圆形变形,但我不知道如何在Photoshop中手动完成,更不用说自动化了。
我的问题
- 我是否朝着正确的方向前进?
- 我的预处理步骤是否正确?
- 如何在OpenCV中自动化这些步骤?
额外信息
我用来获取tesseract OCR结果的命令:
λ tesseract {egg_picture}.jpg --psm 7 stdout
四维超立方体版本:
λ tesseract --version
tesseract 4.0.0-alpha.20170804
leptonica-1.74.4
libgif 4.1.6(?) : libjpeg 8d (libjpeg-turbo 1.5.0) : libpng 1.6.20 : libtiff 4.0.6 : zlib 1.2.8 : libwebp 0.4.3 : libopenjp2 2.1.
平台:Windows 10
编辑1
我在一些鸡蛋标记图像上应用了OpenCV的自适应阈值处理。目前为止,这是结果:
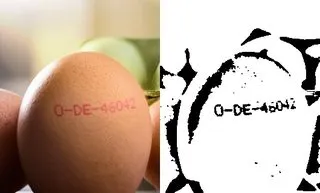






然而,还有很多噪音。我正在努力调整参数,使其在不同图像中都能良好地工作。