我刚开始接触机器学习并正在探索不同的算法。我从互联网上拿了一个二元分类问题,并尝试应用各种机器学习技术。
首先,我尝试在其上运行朴素贝叶斯分类器,发现成功率约为75%。我尝试了逻辑回归,发现成功率惊人达90%。我尝试将正则化应用于我的分类器,下面是当我变换Lambda(正则化参数)超过30个值时所得到的曲线。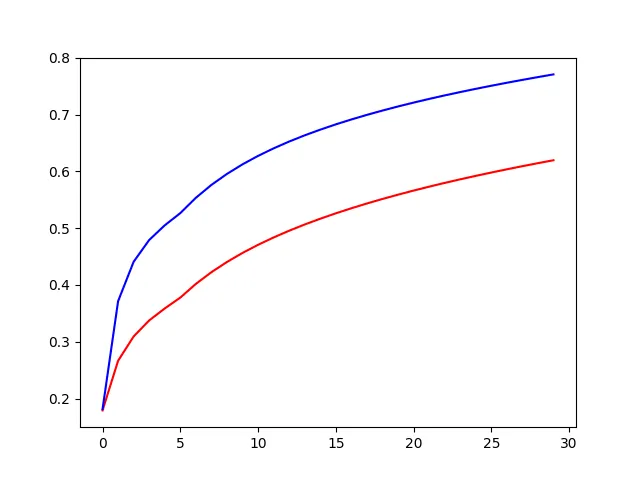 红色曲线是训练集,蓝色曲线是验证集。您可以看到,两条曲线的误差边界都随着Lambda的增加而增加。我认为这表明我的假设一开始就欠拟合,而欠拟合随着Lambda的增加而恶化。这种解释方法正确吗?
红色曲线是训练集,蓝色曲线是验证集。您可以看到,两条曲线的误差边界都随着Lambda的增加而增加。我认为这表明我的假设一开始就欠拟合,而欠拟合随着Lambda的增加而恶化。这种解释方法正确吗?
无论如何,为了解决欠拟合问题,尝试使用更复杂的模型似乎是有道理的,因此我转向了神经网络。我最初的问题有31个特征来描述它,我选择了一个具有两个隐藏层和每层10个节点的网络。
训练后,我发现它仅正确分类了65%的训练数据。这比朴素贝叶斯分类器和逻辑回归还要差。这种情况有多常见?我的神经网络实现是否有问题?
有趣的是,神经网络似乎只在25-30次迭代后就收敛了。我的逻辑回归需要300次迭代才能收敛。我考虑到神经网络可能会陷入局部最小值,但根据我正在学习的 Andrew NG 的机器学习课程,这种情况相当不可能。
从课程上所解释的来看,神经网络通常会给出比逻辑回归更好的预测结果,但您可能会遇到过拟合的问题。然而,我认为这里不是问题,因为65%的成功率是在训练集上获得的。
我需要重新审查一下我的神经网络实现,还是这种情况可能会发生?