这是关于按组获取第一个和最后一个值的后续问题。
如何在每个组内删除第一行和最后一行?
我有这个
由于等于 'c' 和 'd' 的两个 0 级组都少于 3 行,因此应该删除所有行。
如何在每个组内删除第一行和最后一行?
我有这个
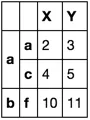
df。df = pd.DataFrame(np.arange(20).reshape(10, -1),
[['a', 'a', 'a', 'a', 'b', 'b', 'b', 'c', 'c', 'd'],
['a', 'a', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']],
['X', 'Y'])
df
我故意让第二行具有与第一行相同的索引值。我无法控制索引的唯一性。
X Y
a a 0 1
a 2 3
c 4 5
d 6 7
b e 8 9
f 10 11
g 12 13
c h 14 15
i 16 17
d j 18 19
我想要这个
X Y
a b 2.0 3
c 4.0 5
b f 10.0 11
由于等于 'c' 和 'd' 的两个 0 级组都少于 3 行,因此应该删除所有行。