拿这个正则表达式举例:/^[^abc]/。它将匹配字符串开头的任何单个字符,但不包括a、b或c。
如果你在它后面加上一个* – /^[^abc]*/ – 正则表达式将继续将每个随后的字符添加到结果中,直到遇到a, 或者b, 或者c为止。
例如,在源字符串"qwerty qwerty whatever abc hello"的情况下,该表达式将匹配到"qwerty qwerty wh"。
但如果我想要匹配字符串为"qwerty qwerty whatever "呢?
换句话说,如何匹配到(但不包括)精确序列"abc"?
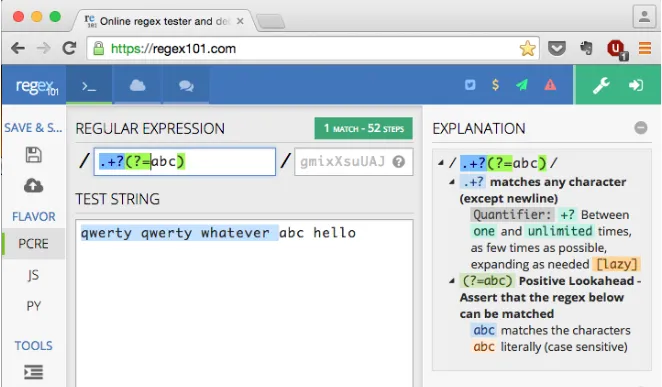
"qwerty qwerty whatever "- 不包括 "abc"。换句话说,我不想匹配结果为"qwerty qwerty whatever abc"。 - callumstring.split('abc')[0]来解决这个问题。虽然这不是官方解答,但我认为这种方法比正则表达式更为简单明了。 - Wylliam Judd