我希望你能提供一个正则表达式,以获取在第一次出现字符
取以下文本为例:
我尝试了这个
:或字符(之前的所有内容,并可选包含空格。取以下文本为例:
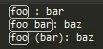
foo : bar
foo bar: baz
foo (bar): baz
预期结果:
<foo>: bar
<foo bar>: baz
<foo> (bar): baz
我尝试了这个
(.*[:\(]),但是得到的结果是:<foo :> bar
<foo bar:> baz
<foo (bar):> baz
请参考https://regex101.com/r/sR4hA5/1
我正在使用Python 3.5。
有什么想法吗?
^(.*)[:\(]怎么样? - Jonathan Parent Lévesque