我在Keras中使用LSTM实现了一个预测模型。数据集是15分钟分隔的,我正在预测未来12步。该模型对于这个问题表现良好。但是预测结果存在一个小偏移效应。要获得更清晰的图片,请参见下面附加的图表。
我还没有为这个预测使数据平稳化。我也尝试过取差分并使模型尽可能平稳,但问题仍然存在。
我也尝试了不同的最小-最大缩放器比例,希望能改善模型。但预测结果变得更糟了。
我了解该模型正在复制最后已知的值,从而尽可能地减少损失。
训练过程中验证和训练损失一直很低。这让我想是否需要为此提出新的损失函数。
是否有必要?如果是,我应该选择哪种损失函数?
我已经尝试了所有我遇到的方法。我找不到任何资源指向这种问题。这是数据的问题吗?这是因为LSTM难以学习这个问题吗?
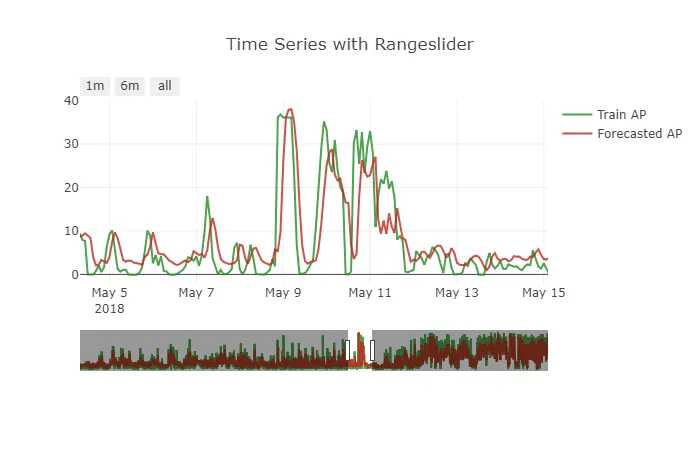
如何处理这个问题?数据必须如何转换以处理这种问题?
我使用的模型如下所示
init_lstm = RandomUniform(minval=-.05, maxval=.05)
init_dense_1 = RandomUniform(minval=-.03, maxval=.06)
model = Sequential()
model.add(LSTM(15, input_shape=(X.shape[1], X.shape[2]), kernel_initializer=init_lstm, recurrent_dropout=0.33))
model.add(Dense(1, kernel_initializer=init_dense_1, activation='linear'))
model.compile(loss='mae', optimizer=Adam(lr=1e-4))
history = model.fit(X, y, epochs=1000, batch_size=16, validation_data=(X_valid, y_valid), verbose=1, shuffle=False)
I made the forecasts like this
my_forecasts = model.predict(X_valid, batch_size=16)
使用此函数将时间序列数据转换为监督学习,以供LSTM使用
# convert time series into supervised learning problem
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols, names = list(), list()
# input sequence (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
names += [('var%d(t-%d)' % (j+1, i)) for j in range(n_vars)]
# forecast sequence (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
if i == 0:
names += [('var%d(t)' % (j+1)) for j in range(n_vars)]
else:
names += [('var%d(t+%d)' % (j+1, i)) for j in range(n_vars)]
# put it all together
agg = concat(cols, axis=1)
agg.columns = names
# drop rows with NaN values
if dropnan:
agg.dropna(inplace=True)
return agg
super_data = series_to_supervised(data, 12, 1)
我的时间序列是多变量的。{{var2}}是我需要预测的变量。我删除了未来的{{var1}}。
del super_data['var1(t)']
像这样分离训练集和验证集
features = super_data[feat_names]
values = super_data[val_name]
ntest = 3444
train_feats, test_feats = features[0:-n_test], features[-n_test:]
train_vals, test_vals = values [0:-n_test], values [-n_test:]
X, y = train_feats.values, train_vals.values
X = X.reshape(X.shape[0], 1, X.shape[1])
X_valid, y_valid = test_feats .values, test_vals .values
X_valid = X_valid.reshape(X_valid.shape[0], 1, X_valid.shape[1])
我还没有为这个预测使数据平稳化。我也尝试过取差分并使模型尽可能平稳,但问题仍然存在。
我也尝试了不同的最小-最大缩放器比例,希望能改善模型。但预测结果变得更糟了。
Other Things I have tried
=> Tried other optimizers
=> Tried mse loss and custom log-mae loss functions
=> Tried varying batch_size
=> Tried adding more past timesteps
=> Tried training with sliding window and TimeSeriesSplit
我了解该模型正在复制最后已知的值,从而尽可能地减少损失。
训练过程中验证和训练损失一直很低。这让我想是否需要为此提出新的损失函数。
是否有必要?如果是,我应该选择哪种损失函数?
我已经尝试了所有我遇到的方法。我找不到任何资源指向这种问题。这是数据的问题吗?这是因为LSTM难以学习这个问题吗?