我经常发现人们在某些情况下得到了一个没有名称的列表,其中包含没有名称的字符向量,他们想要将它们按行绑定到一个data.frame中。以下是一个例子:
library(magrittr)
data <- cbind(LETTERS[1:3],1:3,4:6,7:9,c(12,15,18)) %>%
split(1:3) %>% unname
data
#[[1]]
#[1] "A" "1" "4" "7" "12"
#
#[[2]]
#[1] "B" "2" "5" "8" "15"
#
#[[3]]
#[1] "C" "3" "6" "9" "18"
一种典型的方法是使用基本R中的do.call。
do.call(rbind, data) %>% as.data.frame
# V1 V2 V3 V4 V5
#1 A 1 4 7 12
#2 B 2 5 8 15
#3 C 3 6 9 18
也许一个效率较低的方法是使用R基础包中的Reduce函数。
Reduce(rbind,data, init = NULL) %>% as.data.frame
# V1 V2 V3 V4 V5
#1 A 1 4 7 12
#2 B 2 5 8 15
#3 C 3 6 9 18
然而,当我们考虑像dplyr或data.table这样的更现代的包时,一些可能立即想到的方法不起作用,因为向量是未命名的或不是列表。
library(dplyr)
bind_rows(data)
#Error: Argument 1 must have names
library(data.table)
rbindlist(data)
#Error in rbindlist(data) :
# Item 1 of input is not a data.frame, data.table or list
一种方法是在向量上使用 set_names。
library(purrr)
map_df(data, ~set_names(.x, seq_along(.x)))
# A tibble: 3 x 5
# `1` `2` `3` `4` `5`
# <chr> <chr> <chr> <chr> <chr>
#1 A 1 4 7 12
#2 B 2 5 8 15
#3 C 3 6 9 18
然而,这似乎比它需要的步骤还要多。
因此,我的问题是:如何使用 tidyverse 或 data.table 以有效地将一个未命名的字符向量列表逐行绑定为一个 data.frame?
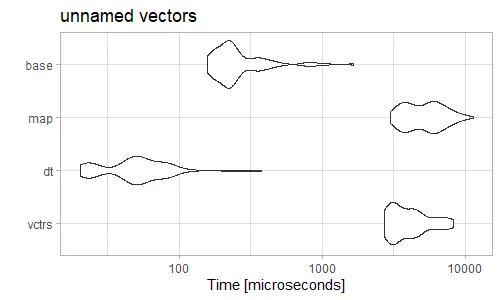
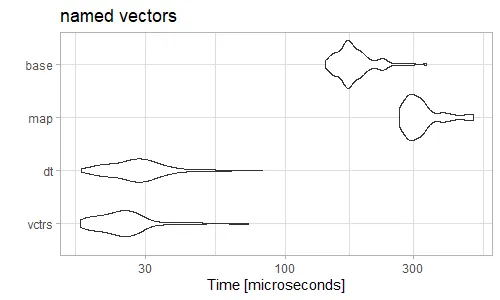
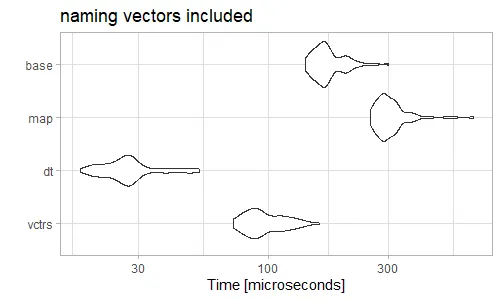
Reduce(rbind,不可能比do.call(rbind,更高效,因为do.call结构只分配内存并复制数据一次,而Reduce结构会重复分配新的内存并重新复制所有以前 "rbinded" 的元素。 - alexis_laz