由于您关心列中的对象是列表,因此我建议使用生成器来去除包装项的列表:
import pandas as pd
import numpy as np
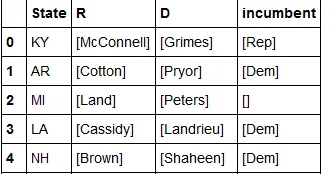
rows = [(u'KY', [u'McConnell'], [u'Grimes'], [u'Rep']),
(u'AR', [u'Cotton'], [u'Pryor'], [u'Dem']),
(u'MI', [u'Land'], [u'Peters'], [])]
def get(r, nth):
'''helper function to retrieve item from nth list in row r'''
return r[nth][0] if r[nth] else np.nan
def remove_list_items(list_of_records):
for r in list_of_records:
yield r[0], get(r, 1), get(r, 2), get(r, 3)
生成器的工作原理类似于此函数,但不同的是它不会在内存中无谓地实例化列表作为中间步骤,而是将列表中每一行要传递给消费者:
def remove_list_items(list_of_records):
result = []
for r in list_of_records:
result.append((r[0], get(r, 1), get(r, 2), get(r, 3)))
return result
然后通过生成器将您的数据组成 DataFrame(或者如果希望,使用列表版本)。
>>> df = pd.DataFrame.from_records(
remove_list_items(rows),
columns=["State", "R", "D", "incumbent"])
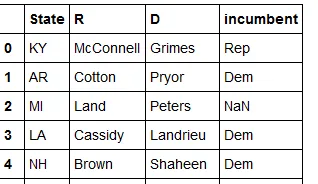
>>> df
State R D incumbent
0 KY McConnell Grimes Rep
1 AR Cotton Pryor Dem
2 MI Land Peters NaN
你也可以使用列表推导式或生成器表达式(如下所示)来实现基本相同的功能:
>>> df = pd.DataFrame.from_records(
((r[0], get(r, 1), get(r, 2), get(r, 3)) for r in rows),
columns=["State", "R", "D", "incumbent"])