我想根据特定列的if条件将给定数据框拆分为两个数据框。目前我是通过两次遍历整个数据框来实现这一点。请建议一些改进方法。
player score
dan 10
dmitri 45
darren 15
xae12 40
就像在上面的数据框中,我希望将数据框分成两个部分,其中一个包含得分低于15的球员行,另一个包含其余行。我只想用一次迭代来完成这个操作。(如果答案适用于 n 个数据框,那会对我很有帮助) 。
有两种可能的方法可以根据您的需求选择数据框。在同一查询中进行时间分析,以便我们可以了解哪种方法更快。
1)使用两个不同的df
%%time
dataframe1 = dataframe[dataframe['score']>15]
dataframe2 = dataframe[dataframe['score']<=15]
输出结果为 Wall time: 4.06 ms
2) 使用布尔和取反概念:
%%time
a = dataframe.score>15
dataframe1 = dataframe[a]
dataframe2 = dataframe[~a]
这个查询的输出时间是Wall time: 0.02 ms
显然,第二种方法要快得多。
IICU
使用布尔选择
m=df.score>15
Lessthan15=df[~m]
Morethan15=df[m]
超过15
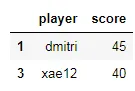
少于15
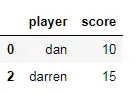
试试这个:
df_less_than_15 = df[df['score'] < 15]
df_more_than_15 = df[df['score'] >= 15]
你可以对每个给定的数据框使用相同的东西。