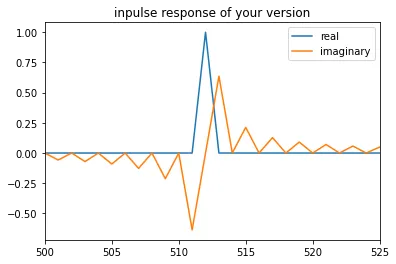
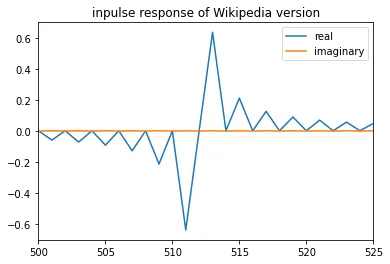
为了对一维数组执行Hilbert变换,需要执行以下步骤:
我有一种感觉,这可能与Numba的CUDA接口本身有关...它是否允许像这样修改数组的单个元素(或数组切片)?我认为它可能会,因为变量
简而言之,使用Numba的
- 对数组进行FFT
- 将数组的一半加倍,另一半清零
- 对结果进行反FFT
def htransforms(data):
N = data.shape[0]
transforms = nb.cuda.device_array_like(data) # Allocates memory on GPU with size/dimensions of signal
transforms.dtype = np.complex64 # Change GPU array type to complex for FFT
pyculib.fft.fft(signal.astype(np.complex64), transforms) # Do FFT on GPU
transforms[1:N/2] *= 2.0 # THIS STEP DOESN'T WORK
transforms[N/2 + 1: N] = 0+0j # NEITHER DOES THIS ONE
pyculib.fft.ifft_inplace(transforms) # Do IFFT on GPU: in place (same memory)
envelope_function = transforms.copy_to_host() # Copy results to host (computer) memory
return abs(envelope_function)
我有一种感觉,这可能与Numba的CUDA接口本身有关...它是否允许像这样修改数组的单个元素(或数组切片)?我认为它可能会,因为变量
transforms是一个numba.cuda.cudadrv.devicearray.DeviceNDArray,所以我想它可能具有一些与numpy的ndarray相同的操作。简而言之,使用Numba的
device_arrays,如何在切片上执行简单操作?我得到的错误是:
unsupported operand type(s) for *=: 'DeviceNDArray' and 'float'
data是什么类型?你对数组的 dtype 的操作看起来非常可疑。 - talonmiescuBLAS.scal(2)和cuBLAS.scal(0)。http://pyculib.readthedocs.io/en/latest/cublas.html - AKX