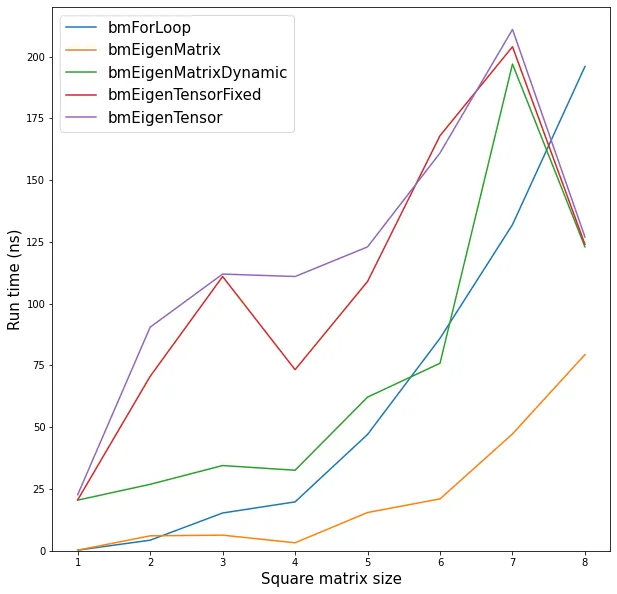
我想用一个3D的Eigen::Tensor代替我的代码中一系列的矩阵。为此,我试图比较Tensor和Matrix的性能。
下面的"tensorContractTest"函数对一个(n,n,n)三阶张量与大小为n的一阶张量进行收缩(n = 500)。这个收缩计算n ** 2个点积,因此在操作数方面,它等价于两个(n, n)矩阵的乘法(下面的"matrixProductTest"函数)。
当在Visual Studio 2013上运行时,"tensorContractTest"函数的运行速度比"matrixProductTest"慢了约40倍。 可能是我漏掉了什么。谢谢帮助。
下面的"tensorContractTest"函数对一个(n,n,n)三阶张量与大小为n的一阶张量进行收缩(n = 500)。这个收缩计算n ** 2个点积,因此在操作数方面,它等价于两个(n, n)矩阵的乘法(下面的"matrixProductTest"函数)。
当在Visual Studio 2013上运行时,"tensorContractTest"函数的运行速度比"matrixProductTest"慢了约40倍。 可能是我漏掉了什么。谢谢帮助。
#include <unsupported/Eigen/CXX11/Tensor>
using namespace Eigen;
// Contracts 3-dimensional (n x n x n) tensor with 1-dimensional (n) tensor.
// By the number of operations, it's equivalent to multiplication of
// two (n, n) matrices (matrixProdTest).
Tensor<double, 2> tensorContractTest(int n)
{
Tensor<double, 3> a(n, n, n); a.setConstant(1.);
Tensor<double, 1> b(n); b.setConstant(1.);
auto indexPair = array<IndexPair<int>, 1>{IndexPair<int>(2,0)};
Tensor<double, 2> result = a.contract(b, indexPair);
return result;
}
MatrixXd matrixProductTest(int n)
{
MatrixXd a = MatrixXd::Ones(n, n), result = a * a;
return result;
}