考虑我有一个包含两列A和B的10行数据帧,如下所示:
在Excel中,我可以像这样计算滚动均值,但要排除第一行: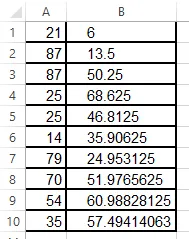
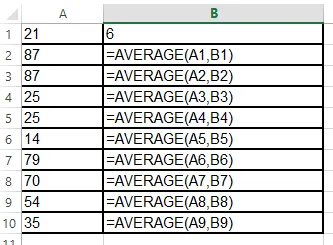 。那么如何在pandas中实现呢?下面是我尝试过的方法:
。那么如何在pandas中实现呢?下面是我尝试过的方法:
这个方法可以得到与Excel匹配的期望结果。但是,有没有更好的使用pandas的方法呢?我尝试使用
A B
0 21 6
1 87 0
2 87 0
3 25 0
4 25 0
5 14 0
6 79 0
7 70 0
8 54 0
9 35 0
在Excel中,我可以像这样计算滚动均值,但要排除第一行:
。那么如何在pandas中实现呢?下面是我尝试过的方法:import pandas as pd
df = pd.read_clipboard() #copying the dataframe given above and calling read_clipboard will get the df populated
for i in range(1, len(df)):
df.loc[i, 'B'] = df[['A', 'B']].loc[i-1].mean()
这个方法可以得到与Excel匹配的期望结果。但是,有没有更好的使用pandas的方法呢?我尝试使用
expanding和rolling,但没有得到期望的结果。