在Java的隐藏特性中,顶部答案提到了双括号初始化,具有非常诱人的语法:
这个习语创建了一个匿名内部类,只在其中初始化实例,它“可以使用包含范围内的任何[...]方法”。
主要问题:这听起来是否像效率低下一样?它的使用应该限制在一次性初始化上吗?(当然还有炫耀!)
第二个问题:新HashSet必须是实例初始化程序中使用的“this”... 有人能解释一下机制吗?
第三个问题:这个习语是否太晦涩难懂,无法在生产代码中使用?
总结:非常好的答案,谢谢大家。对于问题(3),人们认为语法应该清晰(虽然我建议偶尔加上注释,特别是如果您的代码将传递给可能不熟悉它的开发人员)。关于问题(1),生成的代码应该运行快速。额外的.class文件会导致jar文件混乱,并略微减慢程序启动速度(感谢@coobird测量)。@Thilo指出,垃圾回收可能会受到影响,并且加载额外类的内存成本在某些情况下可能是一个因素。
问题(2)最让我感兴趣。如果我理解答案,DBI中发生的事情是匿名内部类扩展了new操作符构造的对象的类,因此具有引用正在构造的实例的“this”值。非常巧妙。
Set<String> flavors = new HashSet<String>() {{
add("vanilla");
add("strawberry");
add("chocolate");
add("butter pecan");
}};
这个习语创建了一个匿名内部类,只在其中初始化实例,它“可以使用包含范围内的任何[...]方法”。
主要问题:这听起来是否像效率低下一样?它的使用应该限制在一次性初始化上吗?(当然还有炫耀!)
第二个问题:新HashSet必须是实例初始化程序中使用的“this”... 有人能解释一下机制吗?
第三个问题:这个习语是否太晦涩难懂,无法在生产代码中使用?
总结:非常好的答案,谢谢大家。对于问题(3),人们认为语法应该清晰(虽然我建议偶尔加上注释,特别是如果您的代码将传递给可能不熟悉它的开发人员)。关于问题(1),生成的代码应该运行快速。额外的.class文件会导致jar文件混乱,并略微减慢程序启动速度(感谢@coobird测量)。@Thilo指出,垃圾回收可能会受到影响,并且加载额外类的内存成本在某些情况下可能是一个因素。
问题(2)最让我感兴趣。如果我理解答案,DBI中发生的事情是匿名内部类扩展了new操作符构造的对象的类,因此具有引用正在构造的实例的“this”值。非常巧妙。
总的来说,DBI 给我留下了一些智力上的好奇。Coobird 和其他人指出,你可以通过 Arrays.asList、varargs 方法、Google Collections 和 Java 7 集合字面量来实现相同的效果。新的 JVM 语言(如 Scala、JRuby 和 Groovy)也提供了简洁的列表构造符号,并与 Java 很好地互操作。考虑到 DBI 混乱了类路径,稍微减慢了类加载速度,并使代码有点更加晦涩,我可能会避开它。但是,我计划向一个刚刚获得 SCJP 认证并热爱有关 Java 语义的友人展示这个技巧!;-) 谢谢大家!
2017年7月:Baeldung 有一个很好的总结 关于双括号初始化,并认为它是一种反模式。
2017年12月:@Basil Bourque 指出,在新的 Java 9 中,你可以这样说:
Set<String> flavors = Set.of("vanilla", "strawberry", "chocolate", "butter pecan");
毫无疑问,这是正确的方法。如果你被困在早期版本中,请看一下Google Collections' ImmutableSet。
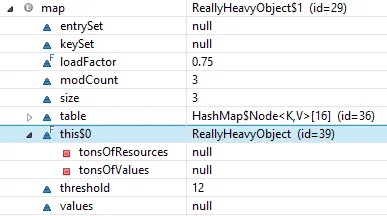
flavors是一个HashSet,但实际上它是一个匿名子类。 - Elazar LeibovichSet<String> flavors = Set.of( "vanilla" , "strawberry" , "chocolate" , "butter pecan" ) ;- Basil Bourque