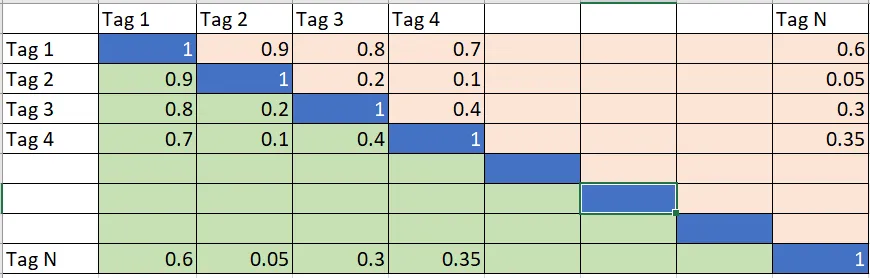
这是我的解决方案(由于我不太了解数据,特别是标签,因此这可能不是最佳方案):
我假设您的数据输入看起来像(长度不固定):
(('tag1', 'tag2', 0.3), ('tag1', 'tag3', 0.4), ('tag1', 'tag4', 0.5),
('tag1', 'tag5', 0.6), ('tag2', 'tag3', 0.5), ('tag2', 'tag4', 0.6),
('tag2', 'tag5', 0.7), ('tag3', 'tag4', 0.7), ('tag3', 'tag5', 0.8),
('tag4', 'tag5', 0.9))
使用Numpy和Pandas:
import numpy as np
import pandas as pd
从收集标签开始(并在此过程中设置DataFrame的索引/列)。 (如果标签背后有一个系统,则我猜这可以进行优化。)
tags = []
for t1, t2, _ in data:
tags += [t1, t2]
tags = index = columns = sorted(list(set(tags)))
然后建立标签和索引之间的映射关系:
tags = dict((t, i) for i, t in enumerate(tags))
然后构建相关矩阵:
correlation = np.identity(len(tags))
for t1, t2, corr in data:
correlation[tags[t1]][tags[t2]] = corr
correlation[tags[t2]][tags[t1]] = corr
最后是 DataFrame:
df = pd.DataFrame(correlation, index=index, columns=columns)
它在我的样本数据中运作良好。