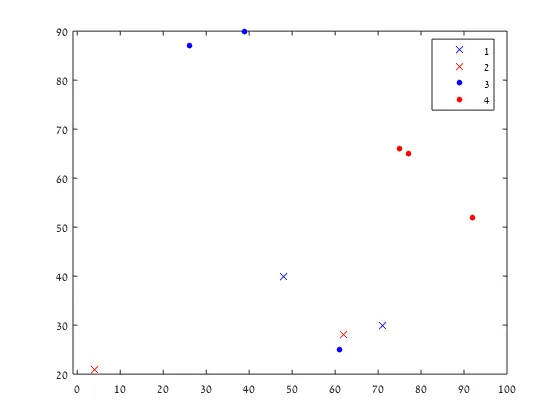
如果
X有很多行,但只有几种
S类型,那么我建议您首先尝试第二种方法。它针对速度进行了优化而不是可读性。如果向量有10个元素,则速度大约是两倍,如果向量有1000个元素,则速度超过200倍。
第一种方法(易于阅读):
无论哪种方法,我认为您都需要一个循环来完成此操作:
hold on
arrayfun(@(n) plot(X(n,1), X(n,2), S{Y(n)}), 1:size(X,1))
或者,按照“传统方式”编写循环:
hold on
for n = 1:size(X,1)
plot(X(n,1), X(n,2), S{Y(n)})
end
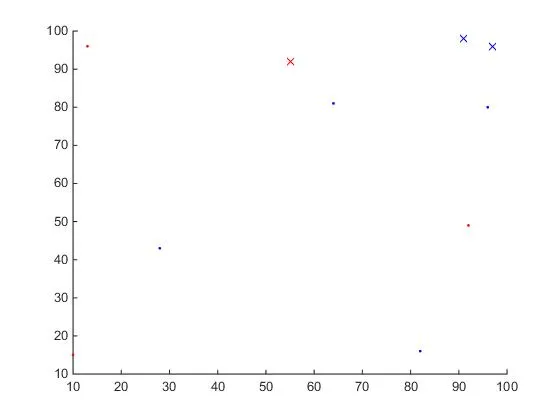
第二种方法(与上述方法相同):
如果您的数据集很大,可以对 Y 进行排序 [Y_sorted, sort_idx] = sort(Y),然后使用 sort_idx 索引 X,如下所示:X_sorted = X(sort_idx);。之后,您可以使用 histc 和 mat2cell 将 X_sorted 分成 4 组,每个组对应一个独立的 Y 值。然后您可以循环遍历这四个组并单独绘制每个组。
这样,无论数据中有多少元素,您只需要循环遍历四个值。如果元素数量很大,这样会更快。
[Y_sorted, Y_index] = sort(Y);
X_sorted = X(Y_index, :);
X_cell = mat2cell(X_sorted, histc(Y,1:numel(S)));
hold on
for ii = 1:numel(X_cell)
plot(X_cell{ii}(:,1),X_cell{ii}(:,2),S{ii})
end
基准测试:
我使用timeit对这两种方法进行了非常简单的基准测试。结果显示第二种方法要快得多:
对于10个元素:
First approach: 0.0086
Second approach: 0.0037
针对1000个元素:
First approach = 0.8409
Second approach = 0.0039