我在SQL性能方面遇到了问题。由于某种突发原因,以下查询非常慢:
我有两个包含特定表的ID的列表。如果第一个列表中的ID已经存在于第二个列表中,我需要删除所有记录。
DECLARE @IdList1 TABLE(Id INT)
DECLARE @IdList2 TABLE(Id INT)
-- Approach 1
DELETE list1
FROM @IdList1 list1
INNER JOIN @IdList2 list2 ON list1.Id = list2.Id
-- Approach 2
DELETE FROM @IdList1
WHERE Id IN (SELECT Id FROM @IdList2)
这两个列表可能包含超过10,000个记录。在这种情况下,每个查询的执行时间都将超过20秒。
执行计划还显示了我不理解的内容。也许这就是为什么它如此缓慢的原因:
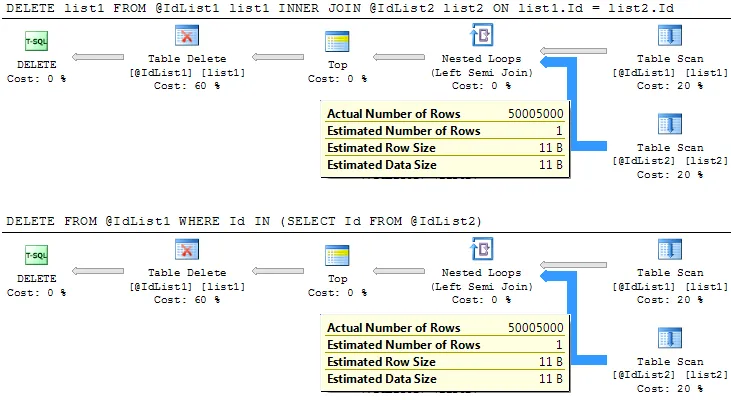
我使用10,000个顺序整数填充了两个列表,因此两个列表的起始点都包含值1-10,000。
正如您所看到的,对于@IdList2,实际行数显示为50,005,000!!。 @IdList1是正确的(实际行数为10,000)
我知道有其他解决方案可以解决此问题,例如填充第三个列表而不是从第一个列表中删除。但我的问题是:
为什么这些删除查询如此缓慢,为什么我会看到这些奇怪的查询计划?