我在我的数据库上运行了以下查询:
SELECT e.id_dernier_fichier
FROM Enfants e JOIN FichiersEnfants f
ON e.id_dernier_fichier = f.id_fichier_enfant
查询运行良好。如果我修改查询如下:
SELECT e.codega
FROM Enfants e JOIN FichiersEnfants f
ON e.id_dernier_fichier = f.id_fichier_enfant
查询变得非常慢!问题在于我想在表e和f中选择许多列,查询可能需要长达1分钟!我尝试了不同的修改,但没有任何效果。我在id_*上也有索引,还有e.codega上的索引。Enfants有9000行,FichiersEnfants有20000行。有什么建议吗?
以下是所需信息(抱歉一开始没有展示它们):
表FichiersEnfants的信息如下:
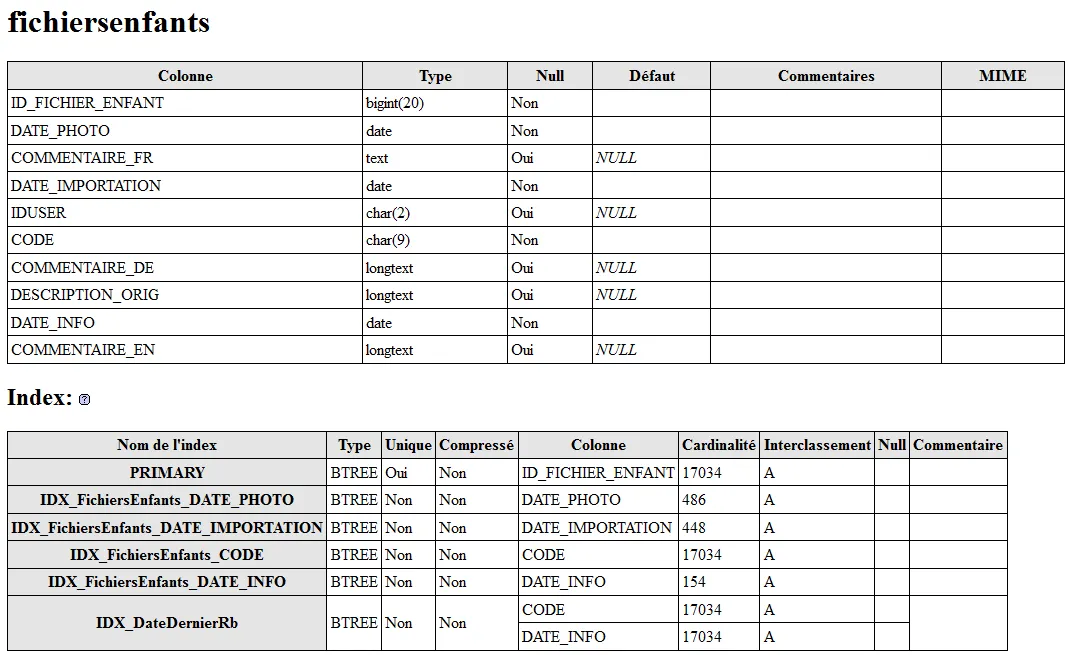 表Enfants的信息如下:
表Enfants的信息如下: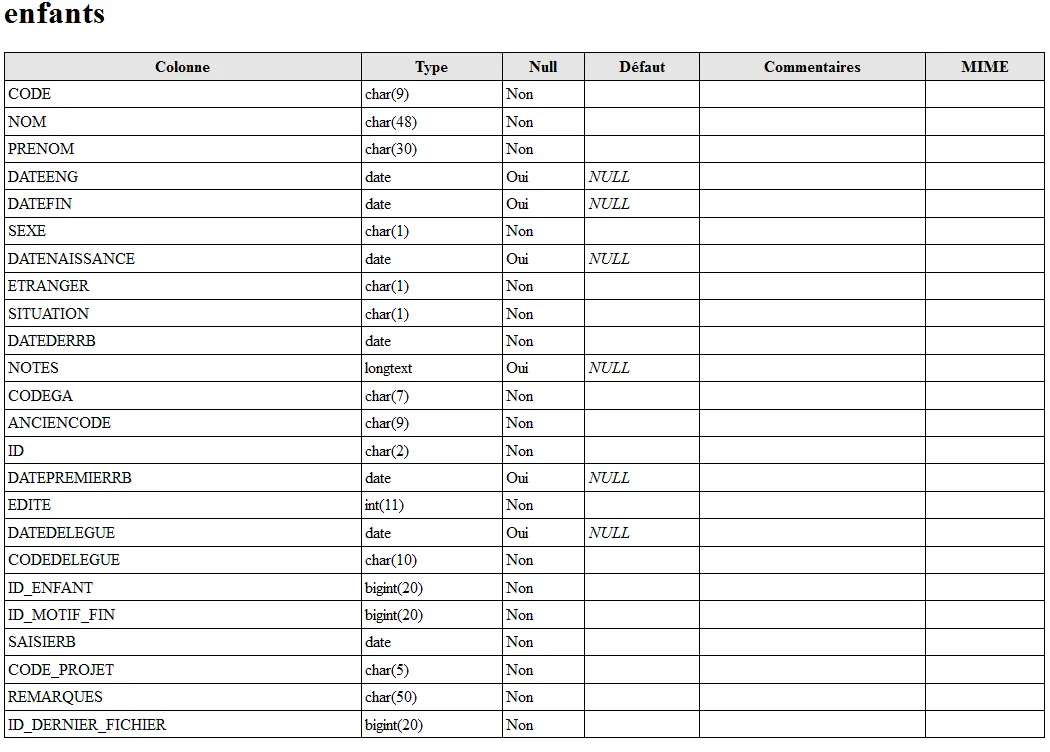 Enfants上的索引如下:
Enfants上的索引如下: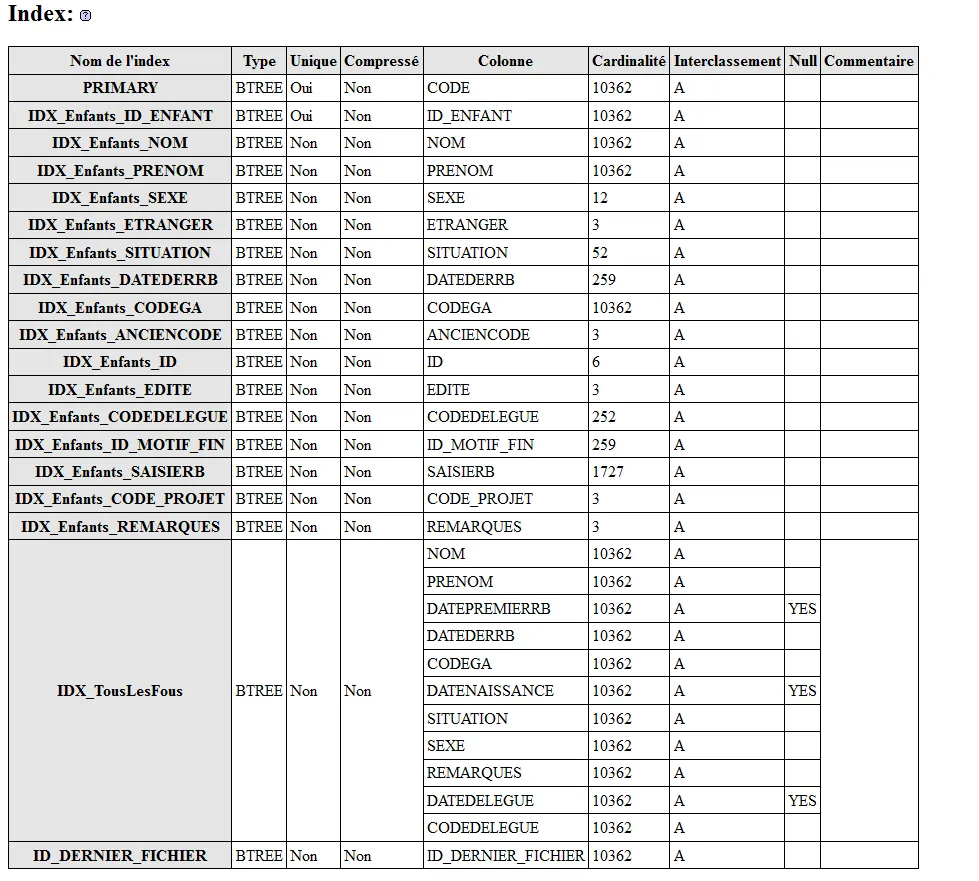 查询1的说明如下:
查询1的说明如下: 查询2的说明如下:
查询2的说明如下: