使用BFS算法处理带权图
50
- user2125722
1
4即使在无权图中,你也不能使用深度优先搜索来寻找最短路径;而广度优先搜索可以做到这一点。 - aspen100
3个回答
68
考虑一个类似于这样的图:
A---(3)-----B
| |
\-(1)-C--(1)/
从A到B的最短路径是经过C(总权重为2)。正常的BFS将直接从A到B,标记B已访问,并从A到C,标记C已访问。
在下一阶段,从C开始传播时,B已被标记为已访问,因此不会将从C到B的路径视为潜在的更短路径,BFS将告诉您从A到B的最短路径具有3的权重。
您可以使用 Dijkstra算法而不是BFS在加权图上找到最短路径。功能上,该算法与BFS非常相似,并且可以用类似于BFS的方式编写。唯一改变的是考虑节点的顺序。
例如,在上面的图中,从A开始,BFS将处理A->B,然后A->C,并停止,因为所有节点都已被访问。
另一方面,Dijkstra算法将按以下方式操作:
- 考虑A到C(因为这是从A开始的最低边缘权重)
- 考虑C到B(因为这是我们迄今为止未考虑的任何已达到节点的最低权重边缘)
- 考虑并忽略A到B,因为B已经被看到。
请注意,差异仅在于检查边的顺序。 BFS将在移动到其他节点之前考虑单个节点的所有边缘,而Dijkstra算法将始终考虑从已看到的节点集合中连接的边缘的最低权重未见过的边缘。听起来有点混乱,但伪代码非常简单:
create a heap or priority queue
place the starting node in the heap
dist[2...n] = {∞}
dist[1] = 0
while the heap contains items:
vertex v = top of heap
pop top of heap
for each vertex u connected to v:
if dist[u] > dist[v] + weight of v-->u:
dist[u] = dist[v] + weight of edge v-->u
place u on the heap with weight dist[u]
这张来自Wikipedia的GIF图很好地展示了发生的事情:
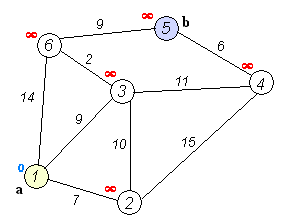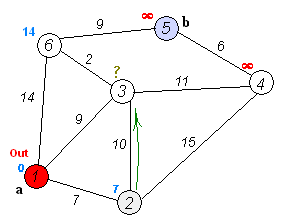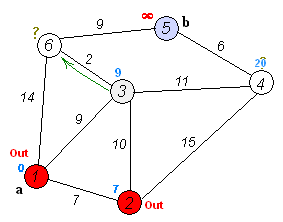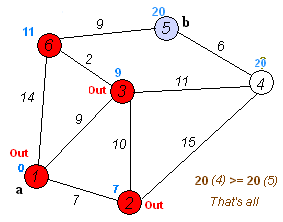
注意,这看起来非常类似于BFS代码,唯一的真正区别在于使用一个按节点距离排序的堆,而不是普通队列数据结构。
- Greg
6
1谢谢您的解释,但是我有一个疑问。您解释了Dijkstra算法如何处理上面的示例,并且选择了从A到C的路径,因为它具有通往C的最低边缘权重。假设,如果C到B的边缘权重为4,而A到D(重量为3)和D到B(重量为1)之间有一条边缘。按照您所说的,A->C和C->B的边缘将首先被遍历,对吗?然后,即使已经看到B,我想还必须遍历A->D和D->B的边缘,否则我们会错过最短路径。那么我们该如何忽略这条路线呢?我想您在第三点中提到了这一点。请纠正我如果我说错了? :/.. 谢谢 - user2125722
@user2125722 首先遍历A->C,因为它是最小权重边,然后是A->B和A->D,接着是D->B,最后是C->B。如果您不明白为什么会这样,请尝试按照该图算法的伪代码进行逐步操作。 - Greg
@user2125722 注意,Dijkstra算法中“seen”的定义略有不同。我更新了代码,以更清晰地反映实际发生的情况。 - Greg
谢谢,我现在明白了。所以,在 Dijkstra 算法中,我们检查每一条路径,但是按照最短未见权重的顺序进行,对吗? - user2125722
1@user2125722 是的,你可以从起始节点开始几条路径,并每次扩展最短的一条/将其分成多条路径。由于迄今为止最短的路径总是首先被处理,无论该路径上有多少边,你总能找到通往目的地的最短路径。 - Greg
如果我错了,请纠正我,但是我不同意第三点的观点,即“考虑并忽略 A --> B,因为 B 已经被看到。”是的,从某种意义上说,我们知道到达 B 需要多长时间,但是由于 A 和 C 的成本较低,B 从未被访问过。算法在访问 B 后将终止(从这个意义上说,C->B 也不应该被处理,因为它已经从 A->C 中被看到)。 - Karen
9
尽管如此,但是在带权图中你可以使用BFS/DFS算法,只需稍微改变一下图的结构。如果你的图中边的权重为正整数,那么你可以用权重为1的n条边替换一条权重为n的边,并插入n-1个中间节点。示例如下:
A-(4)-B
将会是:
A-(1)-M1-(1)-M2-(1)-M3-(1)-B
在最终的BFS/DFS结果中不要考虑这些中间节点(如M1、M2、M3)。
该算法的复杂度为O(V * M),其中M是边权的最大值,如果我们知道在特定的图中M<log V,那么可以考虑使用该算法,但通常情况下该算法的性能可能不是很好。
- Lrrr
5
1谢谢,这是可以做到的,但在权重相当大的情况下可能不可行,对吧? - user2125722
@PartiallyFinite 我明白了。谢谢 :D - user2125722
@Lrrr在您的答案中提到时间复杂度是O(V * M),但它不会像PartiallyFinite所提到的那样取决于边的数量吗? - user2125722
1只有一个更正需要做,其余都是正确的,即使您用n个边和(n-1)个节点替换每个边的权重,也不能使用DFS来找到最短路径。 - Veerendra Singh
@VeerendraSingh 我不认为有什么问题。它似乎等同于Dijkstra算法,尽管效率较低。 - wizzwizz4
2
老师提到BFS / DFS不能直接用于在加权图中查找最短路径。首先,DFS无法用于最短路径。其次,this answer正确解释了为什么BFS在具有循环的加权图上失败,并建议使用Dijkstra's将队列替换为优先队列,并允许在发现新的更短路径时进行松弛操作。然而,没有提到在加权有向无环图(加权DAG)上,Dijkstra算法过于复杂,可以通过按拓扑顺序松弛每个顶点来在
来源:
O(|V|+|E|)时间内找到单源最短路径。这种方法也适用于具有负权重边的DAG。以下是高级算法:distances = {V: infinity for V in vertices}
predecessors = {V: None for V in vertices}
for U in topological_sort(vertices):
for V in adjacencies(U):
if distances[V] > distances[U] + edge_weight(U, V): # relax the edge
distances[V] = distances[U] + edge_weight(U, V)
predecessors[V] = U
来源:
- ggorlen
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接