我刚刚了解到可以使用插值和填充来处理缺失数据/ NaN,我发现插值是一种估计类型,在已知一组离散数据点的范围内构造新的数据点的方法,而填充则是将缺失数据替换为该列的平均值。除此之外还有什么区别吗?何时最好使用它们中的每一个?
2个回答
14
插值
插值(线性)基本上是在两个给定点之间的直线,这两个点之间的数据点缺失:
- 已知两个红点
- 蓝点缺失
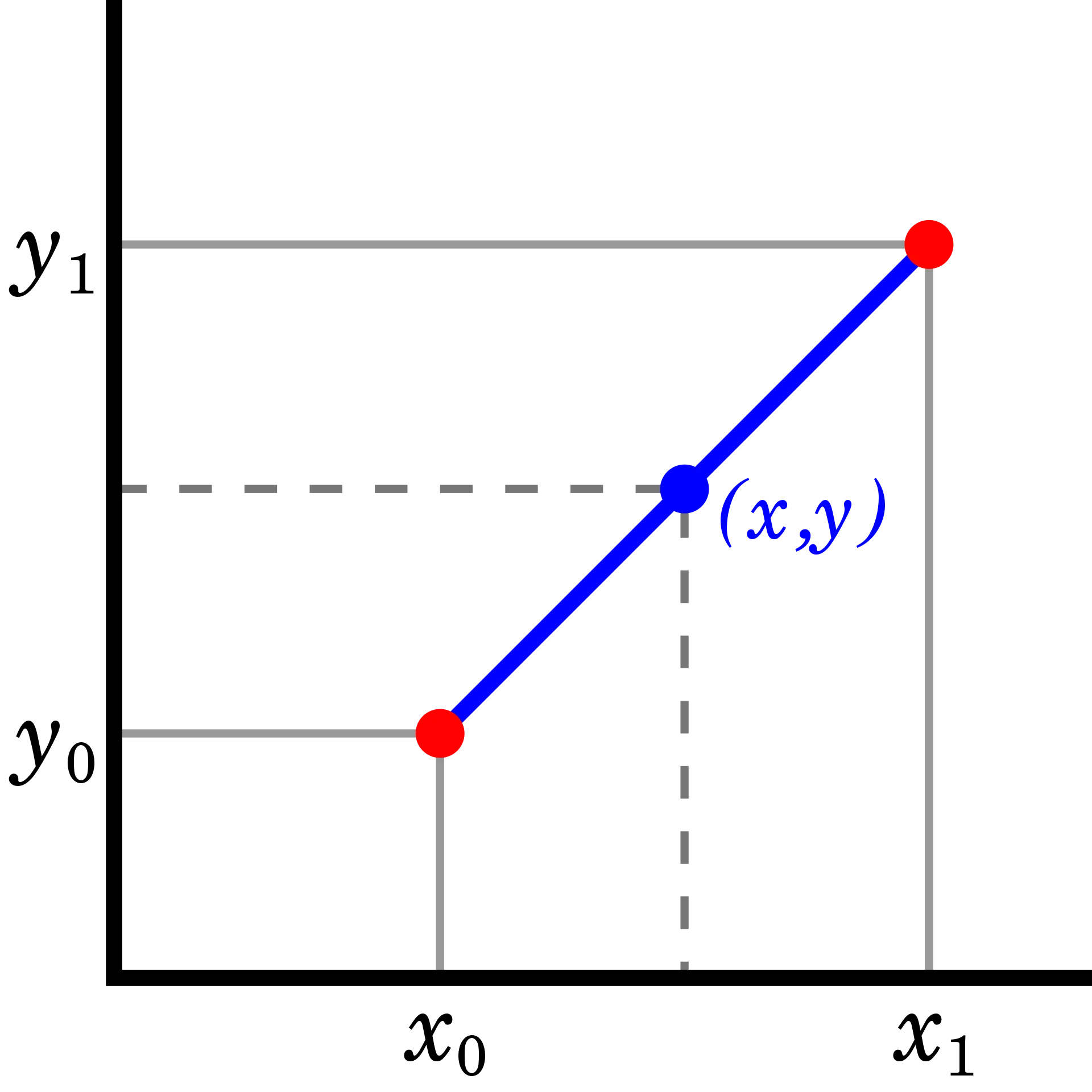
来源:维基百科
好的,解释不错,但用数据来向我展示一下。
首先,线性插值的公式如下:
(y1-y0) / (x1-x0)
假设我们有上面图表中的三个数据点:
df = pd.DataFrame({'Value':[0, np.NaN, 3]})
Value
0 0.0
1 NaN
2 3.0
我们可以看到第一行(蓝点)缺失。
因此根据上述公式:
(3-0) / (2-0) = 1.5
如果我们使用Pandas方法Series.interpolate进行插值:
df['Value'].interpolate()
0 0.0
1 1.5
2 3.0
Name: Value, dtype: float64
对于更大的数据集,它将如下所示:
df = pd.DataFrame({'Value':[1, np.NaN, 4, np.NaN, np.NaN,7]})
Value
0 1.0
1 NaN
2 4.0
3 NaN
4 NaN
5 7.0
df['Value'].interpolate()
0 1.0
1 2.5
2 4.0
3 5.0
4 6.0
5 7.0
Name: Value, dtype: float64
填补缺失值
当我们用 (算术)均值 来填补数据时,我们遵循以下公式:
sum(all points) / n
所以我们的第二个数据帧如下:
(1 + 4 + 7) / 3 = 4
所以,如果我们使用 Series.fillna 和Series.mean 来填充我们的数据框:
df['Value'].fillna(df['Value'].mean())
0 1.0
1 4.0
2 4.0
3 4.0
4 4.0
5 7.0
Name: Value, dtype: float64
- Erfan
1
感谢您的解释。每个na都被插值和填充,每种技术都会给出不同的na值,这对结果的正确性有影响吗?什么时候是实施每种技术的最佳时间?除此之外还有其他差异吗?比如哪种方法更快或者给出最佳结果? - random student
3
我将回答你问题的第二部分,即何时使用哪种技术。我们根据用例使用两种技术。
插值:如果给出一个患有某种疾病(比如肺炎)的患者数据集,并且有一个称为体温的特征。因此,如果该特征存在空值,则可以用平均值替换它,即插值。
内插法:如果给出了一家公司的股票价格数据集,你知道每个周六和周日都是休息日。那么这些值就是缺失值。现在,可以通过周五值和周一值的平均值填充这些值,即内插法。
因此,您可以根据用例选择相应的技术。
- Darshan Jain
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接