我有一个形状为(40,500)的数据框。数据框中的每一行都有一些数值,直到某个变量列号k,之后的所有条目都是NaN。
我想要获取每行中最后一个非NaN列的值。是否有一种方法可以在不循环遍历数据框的所有行的情况下完成此操作?
样本数据框:
2016-06-02 7.080 7.079 7.079 7.079 7.079 7.079 nan nan nan
2016-06-08 7.053 7.053 7.053 7.053 7.053 7.054 nan nan nan
2016-06-09 7.061 7.061 7.060 7.060 7.060 7.060 nan nan nan
2016-06-14 nan nan nan nan nan nan nan nan nan
2016-06-15 7.066 7.066 7.066 7.066 nan nan nan nan nan
2016-06-16 7.067 7.067 7.067 7.067 7.067 7.067 7.068 7.068 nan
2016-06-21 7.053 7.053 7.052 nan nan nan nan nan nan
2016-06-22 7.049 7.049 nan nan nan nan nan nan nan
2016-06-28 7.058 7.058 7.059 7.059 7.059 7.059 7.059 7.059 7.059
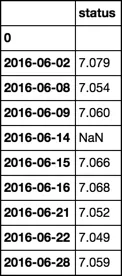
要求的输出
2016-06-02 7.079
2016-06-08 7.054
2016-06-09 7.060
2016-06-14 nan
2016-06-15 7.066
2016-06-16 7.068
2016-06-21 7.052
2016-06-22 7.049
2016-06-28 7.059