我有一个包含大量对象的程序,其中许多是Numpy数组。我的程序交换内存非常严重,我正在尝试减少内存使用,因为当前的内存需求在我的系统上实际上无法完成。
我正在寻找一个好的分析器,可以检查各种对象消耗的内存量(我希望有一个类似于cProfile的内存分析工具),以便我知道在哪里进行优化。
我听说过Heapy不错,但是很遗憾 Heapy 不支持 Numpy 数组,而我的大部分程序都涉及到 Numpy 数组。
我有一个包含大量对象的程序,其中许多是Numpy数组。我的程序交换内存非常严重,我正在尝试减少内存使用,因为当前的内存需求在我的系统上实际上无法完成。
我正在寻找一个好的分析器,可以检查各种对象消耗的内存量(我希望有一个类似于cProfile的内存分析工具),以便我知道在哪里进行优化。
我听说过Heapy不错,但是很遗憾 Heapy 不支持 Numpy 数组,而我的大部分程序都涉及到 Numpy 数组。
如果你在调用许多不同的函数并且不确定交换来自哪里的问题,解决方法之一就是使用memory_profiler中的新绘图功能。首先,您必须用@profile装饰您正在使用的不同函数。为了简单起见,我将使用与memory_profiler一起提供的examples/numpy_example.py示例,其中包含两个函数: create_data()和process_data()
运行脚本时,您不使用Python解释器运行它,而是使用mprof可执行文件。
$ mprof run examples/numpy_example.py
这将创建一个名为mprofile_??????????.dat的文件,其中?将保存代表当前日期的数字。 要绘制结果,只需键入mprof plot即可生成类似于此处所示的图形(如果有多个.dat文件,则始终使用最后一个):
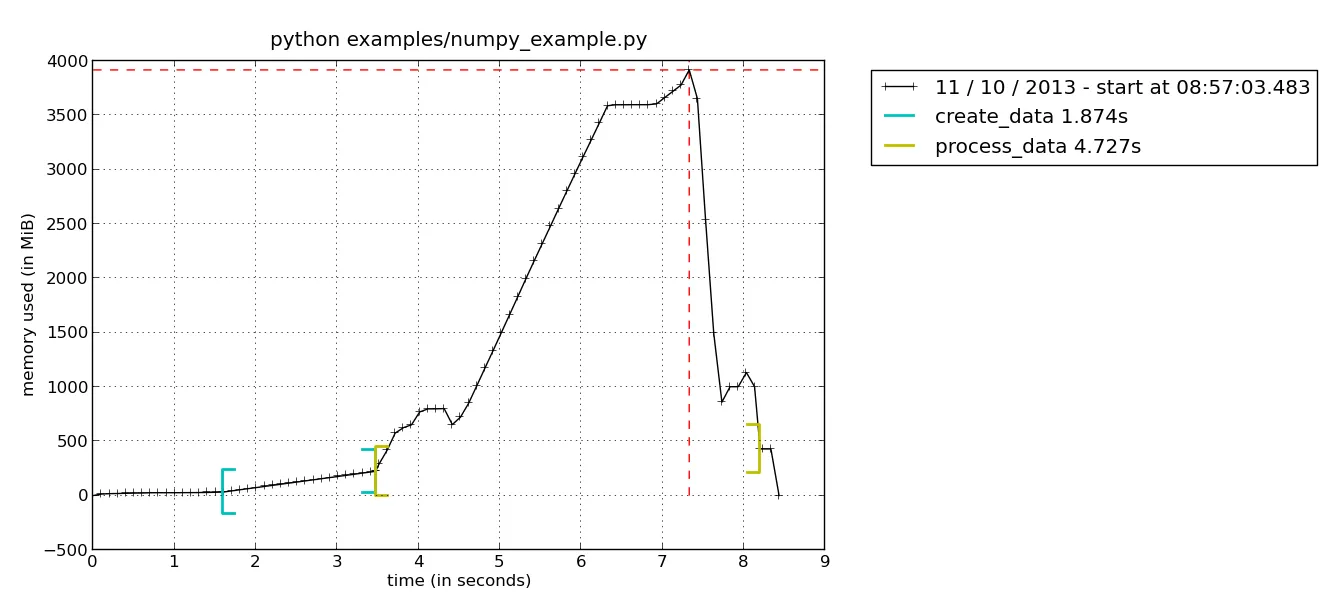
在这里,您可以看到内存消耗情况,括号表示何时进入/离开当前函数。这样就很容易看出函数process_data()的内存消耗峰值。要进一步深入您的功能,可以使用逐行分析器查看函数中每行的内存消耗情况。 运行以下命令:
python -m memory_profiler examples/nump_example.py
这将会给你一个类似于下面的输出:
Line # Mem usage Increment Line Contents
================================================
13 @profile
14 223.414 MiB 0.000 MiB def process_data(data):
15 414.531 MiB 191.117 MiB data = np.concatenate(data)
16 614.621 MiB 200.090 MiB detrended = scipy.signal.detrend(data, axis=0)
17 614.621 MiB 0.000 MiB return detrended
很明显,scipy.signal.detrend正在分配大量内存。
看一下memory profiler。它提供逐行分析和Ipython集成,这使得使用非常容易:
In [1]: import numpy as np
In [2]: %memit np.zeros(1e7)
maximum of 3: 70.847656 MB per loop
更新
正如 @WickedGrey 所提到的,似乎存在一个bug(请参见github问题跟踪器),当调用一个函数超过一次时,我可以重现这个问题:
In [2]: for i in range(10):
...: %memit np.zeros(1e7)
...:
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.894531 MB per loop
maximum of 1: 70.902344 MB per loop
maximum of 1: 70.902344 MB per loop
maximum of 1: 70.902344 MB per loop
maximum of 1: 70.902344 MB per loop
memory_profiler,只是读了一些相关资料,但现在我可以重现这个 bug。我已经更新了我的回答。 - bmuhttps://github.com/numpy/numpy/tree/master/tools/allocation_tracking
track_allocations.py脚本,我将它降至只有4倍,所以我不会再看到那些讨厌的MemoryError了。真是太好了,现在我的工具箱里有了它。 - Stuart Bergmassif 工具来运行 valgrind 吗?valgrind --tool=massif python yourscript.py
这将创建一个名为massif.out.xxx的文件,您可以通过以下方式进行审查:
ms_print massif.out.xxx | less
它有各种有用的信息,但一开始的情节应该是你要寻找的。同时,请查看valgrind主页上的massif教程。
使用valgrind相当高级,可能有更简单的方法可以完成你所需要的功能。
如果你不使用某些数组,你可以将它们保存/封存到临时文件中。这是我过去处理大型数组的方法。当然,这会减慢程序的运行速度,但至少能让程序完成。除非你需要一次性使用所有数组?