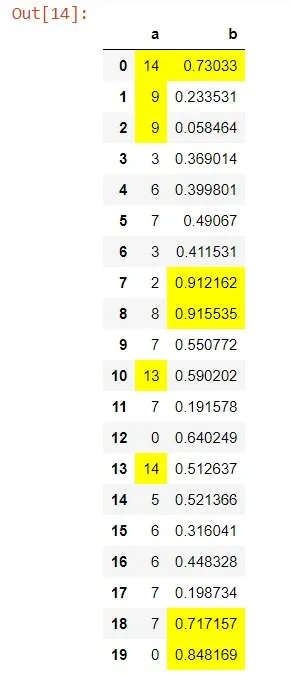
最初的回答:
我用以下代码用黄色突出显示了df中的最大值:
我用以下代码将df中的最大值标记为黄色:def highlight_max(s):
is_max = s == s.max()
return ['background-color: yellow' if v else '' for v in is_max]
pivot_p.style.apply(highlight_max)
现在我想突出显示每列的前5个最大值。 我尝试了以下代码,但它不起作用:
最初的回答:
def highlight_large(s):
is_large = s == s.nlargest(5)
return ['background-color: yellow' if v else '' for v in is_large]
pivot_p.style.apply(highlight_large)
错误:
ValueError: ('Can only compare identically-labeled Series objects', 'occurred at index %_0')