我一直在研究使用Python从PLC传感器中获取数据的解决方案,并且使用cpppo解决了语法等问题,目前已能循环获取标签中的数据。
为了测试这个新的Python cpppo解决方案,我将运行Python逻辑的机器通过VPN隧道连接到了PLC,并让它轮询一个特定的标签/传感器。这个标签也会被不同的非Python解决方案所轮询和记录,该解决方案通过以太网连接到本地机器网络。
为了测试这个新的Python cpppo解决方案,我将运行Python逻辑的机器通过VPN隧道连接到了PLC,并让它轮询一个特定的标签/传感器。这个标签也会被不同的非Python解决方案所轮询和记录,该解决方案通过以太网连接到本地机器网络。
问题
有没有人知道如何简单地重写下面的代码,以便我可以强制它每秒轮询3或4次?还有其他可能导致这种情况的因素吗?
- 通过“contributing to this”,我指的是“other”或“non-Python”方法似乎从同一标签每秒记录3次的poll响应,并且Python cpppo解决方案似乎仅每秒最多轮询2次,因此在一秒钟内有3个权值时会偶尔错过一个权值 - 有时每秒只有2个权值,因此不总是每秒3个权值。
数据
传感器数据以方括号括起来返回,但表示重量的单位为克,具有小数精度。以下是原始数据的一个小样本。
[610.5999755859375]
[607.5]
[623.5999755859375]
[599.7999877929688]
[602.5999755859375]
[610.0]
Python 代码
注意:Python 逻辑将传感器的值写入 csv 文件,但会根据系统日期和时间生成并插入时间戳记录,使用 datetime.now() ,但在此之前我将值转换为字符串,并使用 str() 函数从迭代值中删除方括号,如 str(x).replace('[','').replace(']','')。
from cpppo.server.enip.get_attribute import proxy_simple
from datetime import datetime
import time, csv
CsvFile = "C:\\folder\\Test\\Test.csv"
host = "<IPAddress>"
while True:
x, = proxy_simple(host).read("<TagName>")
with open(CsvFile,"a",newline='') as file:
csv_file = csv.writer(file)
for val in x:
y = str(x).replace('[','').replace(']','')
csv_file.writerow([datetime.now(), y])
#time.sleep(0.05)
问题和测试结果
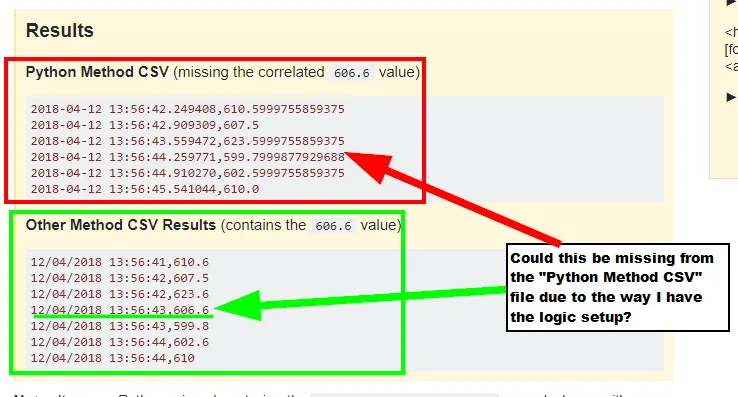
当我将Python捕获的csv文件记录与其他非Python标记捕获方法的记录进行比较时,Python生成的csv记录有时会丢失,而且经常出现这种情况。
值得注意的细节(以防万一)
由于它们在捕获时生成时间戳,因此这两个系统之间存在少于一秒的时间戳差异。
该特定传感器可以在一秒钟内输出三个值,但并不总是如此;有时每秒一个,或每秒两个,或每秒没有。
另一种方法使用Java,但是无法访问此代码以进行逻辑比较。
我正在使用Python版本
3.6.5(v3.6.5:f59c0932b4,2018年3月28日,16:07:46)[MSC v.1900 32位(Intel)],来自Windows 10。
问题说明:Python未能捕获Results
Python Method CSV (missing the correlated
606.6value)2018-04-12 13:56:42.249408,610.5999755859375 2018-04-12 13:56:42.909309,607.5 2018-04-12 13:56:43.559472,623.5999755859375 2018-04-12 13:56:44.259771,599.7999877929688 2018-04-12 13:56:44.910270,602.5999755859375 2018-04-12 13:56:45.541044,610.0Other Method CSV Results (contains the
606.6value)12/04/2018 13:56:41,610.6 12/04/2018 13:56:42,607.5 12/04/2018 13:56:42,623.6 12/04/2018 13:56:43,606.6 12/04/2018 13:56:43,599.8 12/04/2018 13:56:44,602.6 12/04/2018 13:56:44,610
12/04/2018 13:56:43,606.6的记录,而它是从另一个系统记录的。我怀疑这是由于某些微小的延迟造成的,因为我只在与其他非Python捕获的文件进行比较时看到它丢失值。
for val in message循环遍历列表或数组类型的message。因此,每个值都没有方括号。如果message只有一个值,例如['hello'],那么循环遍历message将会得到字符串'hello'作为唯一的循环迭代。如果你确定message总是只有一个值,你可以使用val = message[0]替代for val in message。 - John Zwinck