我需要使用Pyspark检测时间序列上的阈值。
在下面的示例图表中,我想要检测(通过存储相关时间戳)每个参数ALT_STD大于5000然后小于5000的出现次数。
然而,在某些情况下,事件可能是周期性的,我可能会有几个曲线(即ALT_STD会多次升高或降低)。当然,如果我使用以上查询,我只能检测到第一次发生的情况。
我想我应该使用窗口函数和UDF,但我找不到一个可行的解决方案。 我的猜想是算法应该是这样的:
这样的算法在Pyspark中可行吗?怎么做?
附言: 顺便提一下,我知道如何使用udf或udf和内置的sql窗口函数,但不知道如何将udf和窗口函数结合起来。 例如:
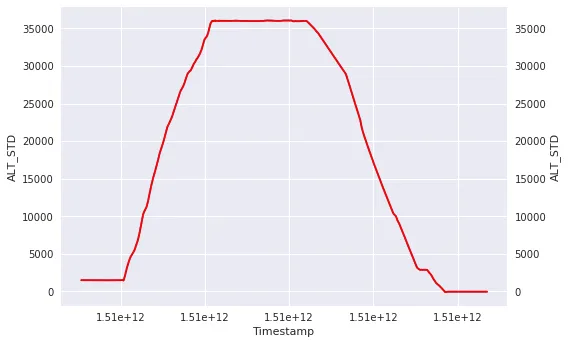
对于这种简单情况,我可以运行简单的查询,例如
t_start = df.select('timestamp')\
.filter(df.ALT_STD > 5000)\
.sort('timestamp')\
.first()
t_stop = df.select('timestamp')\
.filter((df.ALT_STD < 5000)\
& (df.timestamp > t_start.timestamp))\
.sort('timestamp')\
.first()
然而,在某些情况下,事件可能是周期性的,我可能会有几个曲线(即ALT_STD会多次升高或降低)。当然,如果我使用以上查询,我只能检测到第一次发生的情况。
我想我应该使用窗口函数和UDF,但我找不到一个可行的解决方案。 我的猜想是算法应该是这样的:
windowSpec = Window.partitionBy('flight_hash')\
.orderBy('timestamp')\
.rowsBetween(Window.currentRow, 1)
def detect_thresholds(x):
if (x['ALT_STD'][current_row]< 5000) and (x['ALT_STD'][next_row] > 5000):
return x['timestamp'] #Or maybe simply 1
if (x['ALT_STD'][current_row]> 5000) and (x['ALT_STD'][current_row] > 5000):
return x['timestamp'] #Or maybe simply 2
else:
return 0
import pyspark.sql.functions as F
detect_udf = F.udf(detect_threshold, IntegerType())
df.withColumn('Result', detect_udf(F.Struct('ALT_STD')).over(windowSpec).show()
这样的算法在Pyspark中可行吗?怎么做?
附言: 顺便提一下,我知道如何使用udf或udf和内置的sql窗口函数,但不知道如何将udf和窗口函数结合起来。 例如:
# This will compute the mean (built-in function)
df.withColumn("Result", F.mean(df['ALT_STD']).over(windowSpec)).show()
# This will also work
divide_udf = F.udf(lambda x: x[0]/1000., DoubleType())
df.withColumn('result', divide_udf(F.struct('timestamp')))