我有两个数据框,都有一个可能有重复的关键列,但是数据框大多数具有相同的重复键。我想在该键上合并这些数据框,但是在这种情况下,当两个数据框具有相同的重复项时,应分别合并这些重复项。此外,如果一个数据框比另一个数据框具有更多的关键字重复项,我希望它的值填充为NaN。例如:
df1 = pd.DataFrame({'key': ['K0', 'K1', 'K2', 'K2', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3', 'A4', 'A5']},
columns=['key', 'A'])
df2 = pd.DataFrame({'B': ['B0', 'B1', 'B2', 'B3', 'B4', 'B5', 'B6'],
'key': ['K0', 'K1', 'K2', 'K2', 'K3', 'K3', 'K4']},
columns=['key', 'B'])
key A
0 K0 A0
1 K1 A1
2 K2 A2
3 K2 A3
4 K2 A4
5 K3 A5
key B
0 K0 B0
1 K1 B1
2 K2 B2
3 K2 B3
4 K3 B4
5 K3 B5
6 K4 B6
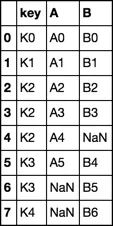
我将尝试获得以下输出。
key A B
0 K0 A0 B0
1 K1 A1 B1
2 K2 A2 B2
3 K2 A3 B3
6 K2 A4 NaN
8 K3 A5 B4
9 K3 NaN B5
10 K4 NaN B6
基本上,我想将重复的 K2 键视为 K2_1、K2_2……然后在数据框上执行 how='outer' 合并。你有什么想法吗?