在下面的代码中,他们使用自编码器作为有监督的聚类或分类,因为他们有数据标签。但是,如果我没有数据标签,可以使用自编码器来聚类数据吗?
关于此问题的更多信息,请参见http://amunategui.github.io/anomaly-detection-h2o/。
谢谢。
2个回答
9
深度学习自编码器始终是无监督学习。您链接的文章中“监督”部分是为了评估其表现如何。
下面的例子(摘自我的书《使用H2O进行实用机器学习》第7章,我在其中尝试将所有H2O无监督算法应用于相同的数据集 - 请原谅广告)采用563个特征,并尝试将它们编码到只有两个隐藏节点中。
第二个命令提取了隐藏节点的权重。`f`是一个数据帧,有两列数值型数据,每一行对应于`tfidf`源数据中的每一行。我只选择了两个隐藏节点,这样我就可以画出聚类图:
顺便说一下,我用以下代码制作了上面的图:
下面的例子(摘自我的书《使用H2O进行实用机器学习》第7章,我在其中尝试将所有H2O无监督算法应用于相同的数据集 - 请原谅广告)采用563个特征,并尝试将它们编码到只有两个隐藏节点中。
m <- h2o.deeplearning(
2:564, training_frame = tfidf,
hidden = c(2), auto-encoder = T, activation = "Tanh"
)
f <- h2o.deepfeatures(m, tfidf, layer = 1)
第二个命令提取了隐藏节点的权重。`f`是一个数据帧,有两列数值型数据,每一行对应于`tfidf`源数据中的每一行。我只选择了两个隐藏节点,这样我就可以画出聚类图:
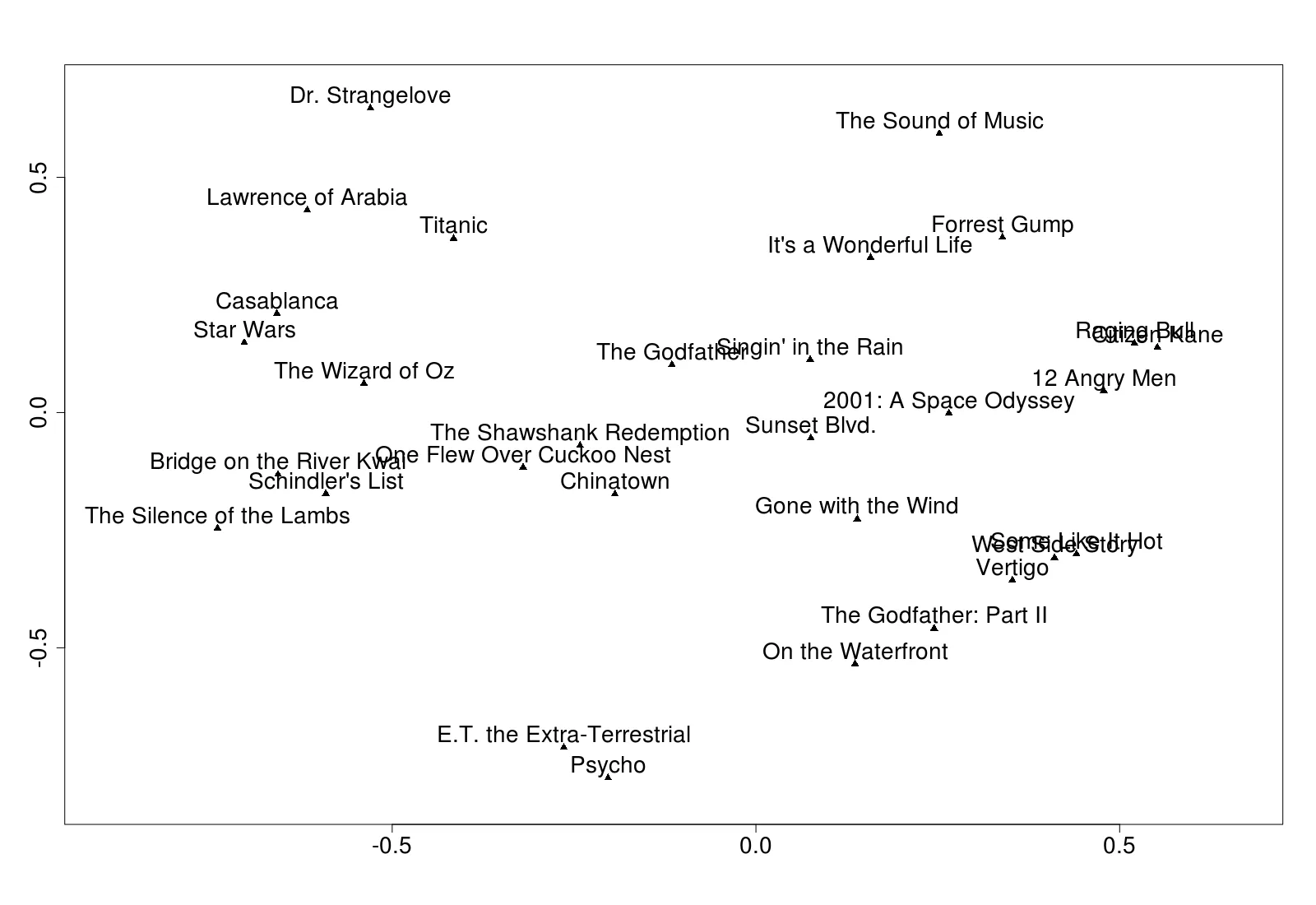
顺便说一下,我用以下代码制作了上面的图:
d <- as.matrix(f[1:30,]) #Just first 30, to avoid over-cluttering
labels <- as.vector(tfidf[1:30, 1])
plot(d, pch = 17) #Triangle
text(d, labels, pos = 3) #pos=3 means above
(注:原始数据来源于Brandon Rose的优秀文章,介绍使用NLTK进行聚类分析。)
- Darren Cook
16
1
在某些方面,编码数据和聚类数据共享一些重叠的理论。因此,您可以使用自动编码器对数据进行聚类(编码)。
一个简单的可视化示例是,如果您有一组训练数据,怀疑其中有两个主要类别。例如共和党人和民主党人的选民历史数据。如果您使用自动编码器将其编码为两个维度,然后将其绘制在散点图上,这种聚类就变得更加清晰。下面是我其中一个模型的样本结果。您可以看到两个类别之间有明显的分裂,以及一些预期的重叠。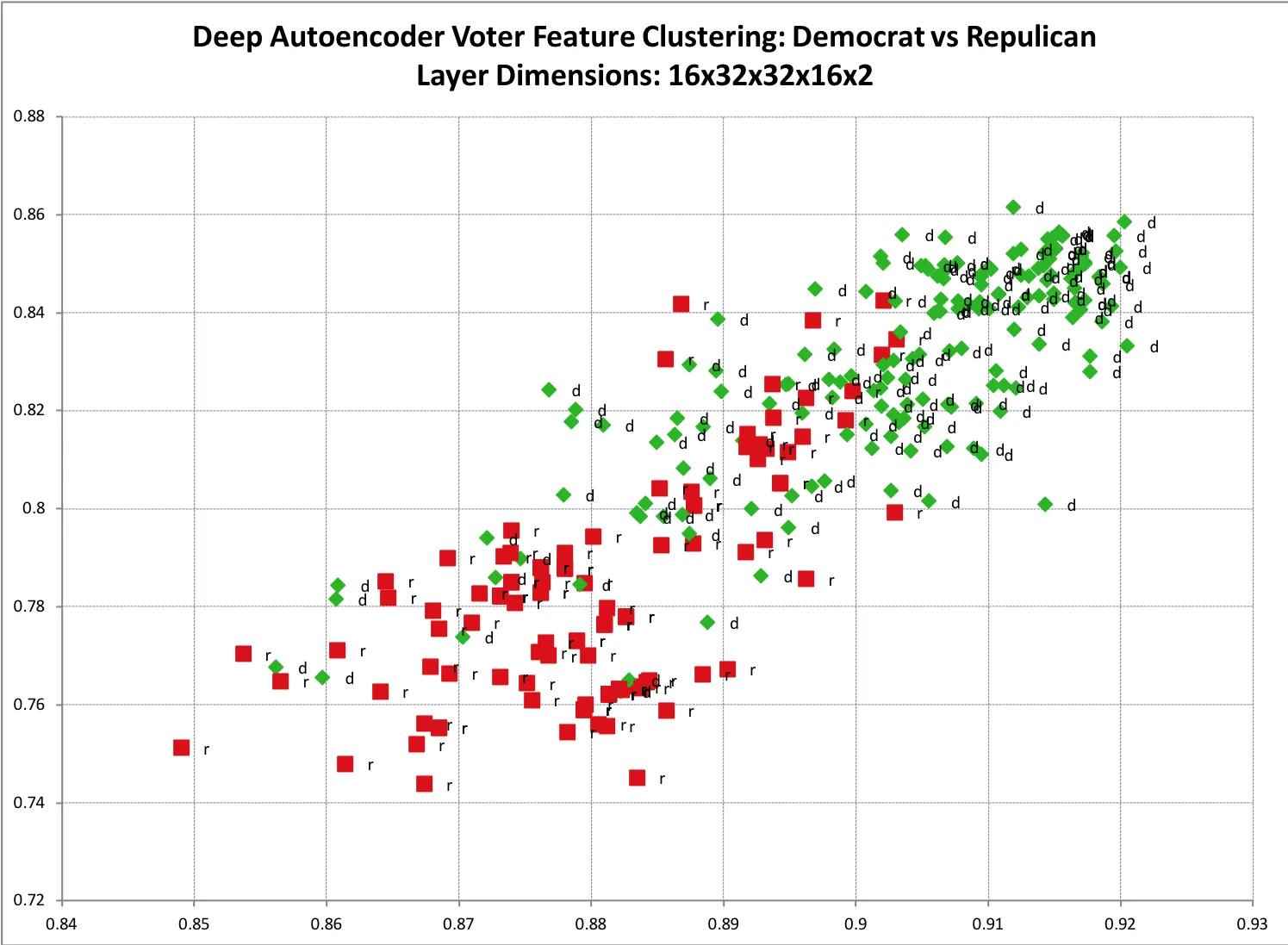 代码可以在这里找到。
代码可以在这里找到。
这种方法不仅需要两个二进制类别,您还可以对尽可能多的不同类别进行训练。只是两个极化的类别更容易可视化。
这种方法不仅限于两个输出维度,那只是为了方便绘图。实际上,你可能会发现将某些大维度空间有意义地映射到这么小的空间很困难。
在编码(聚类)层维度较大的情况下,"可视化"特征簇就不那么清晰了。这时就需要使用某种形式的监督学习来将编码(聚类)特征映射到你的训练标签。
一些确定特征所属类别的方法是将数据输入到knn聚类算法中。或者,我更喜欢将编码向量传递给标准反向误差传播神经网络。请注意,根据你的数据,你可能会发现直接将数据泵入反向传播神经网络中就足够了。
一个简单的可视化示例是,如果您有一组训练数据,怀疑其中有两个主要类别。例如共和党人和民主党人的选民历史数据。如果您使用自动编码器将其编码为两个维度,然后将其绘制在散点图上,这种聚类就变得更加清晰。下面是我其中一个模型的样本结果。您可以看到两个类别之间有明显的分裂,以及一些预期的重叠。
代码可以在这里找到。这种方法不仅需要两个二进制类别,您还可以对尽可能多的不同类别进行训练。只是两个极化的类别更容易可视化。
这种方法不仅限于两个输出维度,那只是为了方便绘图。实际上,你可能会发现将某些大维度空间有意义地映射到这么小的空间很困难。
在编码(聚类)层维度较大的情况下,"可视化"特征簇就不那么清晰了。这时就需要使用某种形式的监督学习来将编码(聚类)特征映射到你的训练标签。
一些确定特征所属类别的方法是将数据输入到knn聚类算法中。或者,我更喜欢将编码向量传递给标准反向误差传播神经网络。请注意,根据你的数据,你可能会发现直接将数据泵入反向传播神经网络中就足够了。
- Kenny Cason
3
"我更喜欢的做法是将编码向量传递给标准反向误差传播神经网络。" - 你好,您能详细说明一下或者提供一个例子吗? - Chandra
1假设你想将一组图像分类为色情/非色情,输入图像大小为[500x500](250,000维向量)。我们的输出将是一个2维向量:[0,1]=色情,[1,0]非色情。可以想象,250,000维向量非常庞大,包含了大量信息。逻辑上的第一步可能是首先对图像数据进行自编码器训练,将图像数据“压缩”成较小的向量,通常称为特征因子(例如250个维度),然后使用标准反向传播数字网络训练图像特征向量。 - Kenny Cason
1自编码器训练的特征向量理想情况下包含更少的噪音,以及更多关于原始图像的“重要”信息。并且由于体积较小,使它们更适合在较小的神经网络中进行训练,例如通过反向误差传播,因为它需要过滤/学习的信息更少。 - Kenny Cason
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接
h2o.scoreHistory(m)获取数据)。 - Darren Cook