我从一个Excel文件中读取数据,它长这样:
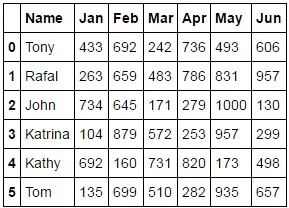
import pandas as pd
mb2 = pd.read_excel('C:\\Users\\IBM_ADMIN\\Desktop\\ml-1m\\工作簿1.xlsx', sheetname='Sheet3')
mapping = {'Jan':'Q1','Feb':'Q1','Mar':'Q1','Apr':'Q2','May':'Q2','Jun':'Q2'}
mb2.groupby(by=mapping,axis=1).sum()
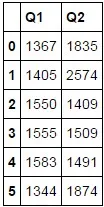
如何显示字段名称?我尝试这样做,但它没有起作用:
mb2.groupby(by=(mapping,'Name'),axis=1).sum()