极小极大算法已被广泛用于两人游戏,如井字棋。我需要为坦克游戏编写人工智能。在这个游戏中,坦克必须在迷宫中移动,而迷宫中有墙壁等障碍物。目标是收集硬币堆。如果只有两位玩家,则可以实现极小极大算法。但如何为多于两名的玩家实现它呢? 因为在每个回合中,每个玩家都会尽力最大化自己的胜利优势。我不能把所有玩家都视为一个敌人,试图通过创建原始极小极大算法中的两个玩家级别来减少只有我自己的胜利优势。 如果问题格式不好,请谅解。我还是新来这个论坛的。
3个回答
24
Mihai Maruseac部分正确地说MiniMax不能再使用了。如果“MiniMax”指的是MiniMax的“标准变体”,那么他是完全正确的!(这就是他的意思。)然而,你也可以将MiniMax视为MaxiMax,其中两个玩家各自最大化自己的奖励(这正是AlphaWolf在问题中写的)。因此,n个玩家的泛化被称为Max^n,仍然可以视为某种程度上的MiniMax。无论如何,下面我将解释为什么标准的2人MiniMax确实不能在3人或更多人的多人游戏中使用。然后,最后,我会给出正确的替代方案的参考资料,即Max^n算法。
因此,让我们首先考虑是否可以通过将所有对手视为Min-Player将2人MiniMax简单地转化为n人MiniMax,即他们都将尝试最小化MAX玩家的奖励。
哦,你不能!让我解释一下为什么。
首先,请记住MiniMax始终只考虑2人零和博弈。因此,MiniMax通常只用单个游戏结果来描述。但是,从技术上讲,有两个! MAX玩家和MIN玩家的结果。因此,为了超级正式正确,每个搜索节点都必须给出一个2元组作为游戏结果,例如(payoff-P1,payoff-P2),其中payoff-P1是P1(MAX)的结果,而payoff-P2是P2(MIN)的结果。然而,由于我们通常考虑零和游戏,我们知道它们的总和总是等于零的,即payoff-P1 + payoff-P2 = 0。因此,我们总是可以推断出另一个人的胜利,因此只从P1的角度表示结果。此外,最小化payoff-P2与最大化payoff-P1相同。
对于几乎所有的游戏(除了在现实生活中心理因素起作用时,比如为了报复而不关心自己的损失),我们始终假设所有代理都是理性的。当我们谈论超过两个玩家时,这将非常重要!什么是理性?每个玩家的目标都是最大化他们自己的奖励(!),再次假设所有其他玩家也都是理性的。
回到2人零和:我们利用/假设了理性,因为P1(MAX)已经通过定义最大化了他的回报,而MIN也正在最大化他自己的回报,因为他正在最小化MAX的回报(由于零和,这与最大化MIN的回报相同)。因此,两个玩家都在最大化自己的奖励,因此玩得理性。
现在假设我们有超过2个玩家,比如3个,为简单起见。
现在让我们看看是否可以通过MIN玩家来替换所有对手(有时建议这样做,因为从教学的角度来看很有用)。如果我们这样做,两者都只会最小化MAX玩家的奖励,而MAX玩家继续最大化自己的奖励。然而,从语义上讲,这意味着两个敌人共同对抗MAX。这种合作违反了我们理性的假设,即玩家们不再最大化自己的奖励!(因此,仅最小化MAX的奖励仅在有两个玩家时等同于最大化自己的奖励,而如果超过两个玩家,则不等同。)我举一个例子来说明:
C.A. Luckhardt和K.B. Irani在“An algorithmic solution of N-person games”中描述了
因此,让我们首先考虑是否可以通过将所有对手视为Min-Player将2人MiniMax简单地转化为n人MiniMax,即他们都将尝试最小化MAX玩家的奖励。
哦,你不能!让我解释一下为什么。
首先,请记住MiniMax始终只考虑2人零和博弈。因此,MiniMax通常只用单个游戏结果来描述。但是,从技术上讲,有两个! MAX玩家和MIN玩家的结果。因此,为了超级正式正确,每个搜索节点都必须给出一个2元组作为游戏结果,例如(payoff-P1,payoff-P2),其中payoff-P1是P1(MAX)的结果,而payoff-P2是P2(MIN)的结果。然而,由于我们通常考虑零和游戏,我们知道它们的总和总是等于零的,即payoff-P1 + payoff-P2 = 0。因此,我们总是可以推断出另一个人的胜利,因此只从P1的角度表示结果。此外,最小化payoff-P2与最大化payoff-P1相同。
对于几乎所有的游戏(除了在现实生活中心理因素起作用时,比如为了报复而不关心自己的损失),我们始终假设所有代理都是理性的。当我们谈论超过两个玩家时,这将非常重要!什么是理性?每个玩家的目标都是最大化他们自己的奖励(!),再次假设所有其他玩家也都是理性的。
回到2人零和:我们利用/假设了理性,因为P1(MAX)已经通过定义最大化了他的回报,而MIN也正在最大化他自己的回报,因为他正在最小化MAX的回报(由于零和,这与最大化MIN的回报相同)。因此,两个玩家都在最大化自己的奖励,因此玩得理性。
现在假设我们有超过2个玩家,比如3个,为简单起见。
现在让我们看看是否可以通过MIN玩家来替换所有对手(有时建议这样做,因为从教学的角度来看很有用)。如果我们这样做,两者都只会最小化MAX玩家的奖励,而MAX玩家继续最大化自己的奖励。然而,从语义上讲,这意味着两个敌人共同对抗MAX。这种合作违反了我们理性的假设,即玩家们不再最大化自己的奖励!(因此,仅最小化MAX的奖励仅在有两个玩家时等同于最大化自己的奖励,而如果超过两个玩家,则不等同。)我举一个例子来说明:
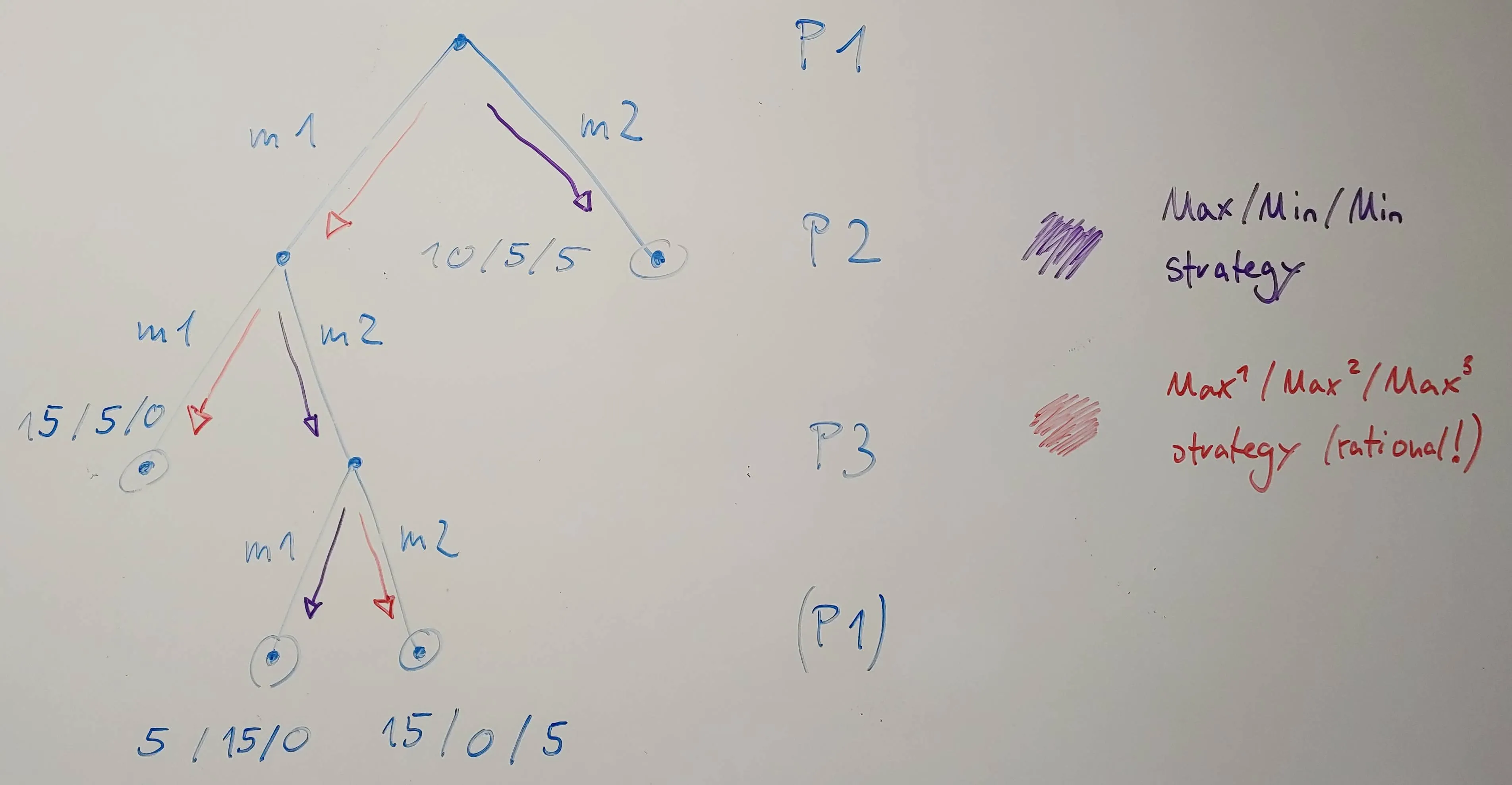
- 像往常一样,我们有一个博弈树,三个玩家(P1,P2,P3)轮流进行。每个玩家有两次机会。最迟在3步之后游戏结束(技术上说,P1还需要进行一次回合,但是两种状态都是最终/叶子节点,因此游戏结束)。游戏描述了一个3人零和游戏(尽管不再需要零和!所有描述的内容也适用于没有这种假设的情况!)。
- 最大赢得20分,分配给3名玩家。(请注意,在我的版本中,所有胜利都是积极的。但是,它仍然是零和游戏,因为所有胜利总和恰好相等,因此可以轻松地将其转换为所有胜利始终加起来为零的游戏。)胜利显示为元组“支付-P1 / 支付-P2 / 支付-P3”。
- 此外,我展示了各自玩家追求的策略,使用了两种不同的颜色:紫色是假定只有P1是MAX玩家,并且其他人只是最小化其奖励的策略(不关心自己的奖励)。红色显示了“理性”策略,假定所有玩家都是MAX玩家,即最大化自己的奖励。
那么,如果将P2和P3视为MIN玩家,游戏会发生什么?他们将最小化P1的奖励,因此P1认为在玩m1时只会获得5分,因为P2可以通过玩m2来最小化P1的奖励。因此,P1将选择它的第二步m2,赢得(仅)10分。
然而,这种假设两个对手都是MIN玩家的情况可以被视为两个玩家的合作(这是不理性的)。因为在假设理性的情况下,玩家P2永远不会玩m2,因为实际上P3将会玩m3(以便P3赢得5分而不是0分)。但是,假设所有对手都最小化P1将使P2选择m2,因为这使P3能够玩m1,从而将P1的胜利减少到5(如果P3按理性方式玩,则胜利为15)。因此,使用MAX / MIN / MIN策略可以找到(或假设)对手协作反对P1 / MAX的策略,在现实中(假设理性)永远不会发生!因此,将MiniMax适应于超过2个玩家显然是错误的。 (在一定程度上,即检测绝不会发生的情况时过于悲观。)我们可以看到,在假设理性代理的情况下,P1应该玩m1而不是m2,从而赢得15分而不仅仅是10分。
这是为了说明MiniMax必须以“不同”的方式扩展。
显然,只需按照上述方法,用向量分别表示每个玩家的结果。与其根据轮到谁来最大化或最小化,我们始终最大化当前玩家的结果。因此,得出的算法也被称为n人Max^n。请注意,MiniMax只是使用元组(支付-P1,支付-P2)的Max^2,其中定义了payoff-P2为-payoff-P1。C.A. Luckhardt和K.B. Irani在“An algorithmic solution of N-person games”中描述了
Max^n算法,收录于第五届人工智能国家会议论文集(AAAI'86),第158-162页,由AAAI Press出版。该论文可公开获取:https://www.aaai.org/Papers/AAAI/1986/AAAI86-025.pdf
请注意,由于搜索空间(即游戏树)呈指数级增长,实际上从不使用MiniMax,因此也从不使用Max^n。相反,人们总是使用Alpha/Beta剪枝,这是一种相当直观的扩展,可以避免访问/探索树的无意义分支。Alpha/Beta也被扩展为适用于n个玩家(n>2)的游戏,Richard Korf在《人工智能》48(1991)中描述了这一点,第99-111页。该文章可公开获取:https://www.cc.gatech.edu/~thad/6601-gradAI-fall2015/Korf_Multi-player-Alpha-beta-Pruning.pdf
最后,让我补充一点非常有趣的观察结果:
在二人零和MiniMax中,计算出的策略是“完美的”,因为它肯定会至少实现由MiniMax保证/计算的胜利。如果对手玩得不理性,即偏离其策略,则结果只能更高。
但在n人零和MiniMax中,即Max^n,情况就不再如此!回想一下,P1的理性策略是玩m1,从而赢得15(如果对手理性地玩)。然而,如果对手不理性地玩m2,那么P1的输出完全取决于P3的行动,因此P1也可能赢得更少。原因在于,在二人零和中,对手的行动直接影响自己的结果--仅限于这种情况!但是,对于三个或更多的玩家,胜利也可以分配给其他玩家。- Prof.Chaos
3
3有趣的事实关于 MiniMax 和 Max^n:显然已经证明存在病态情况,即“搜索更深”,但不是到游戏的最后(因为那时我们将拥有完美的信息),可以导致计算结果的价值降低。Dana Nau 等人已经为(双人)MiniMax 显示了这一点。其在 Max^n 上的推广由 D. Mutchler 在“The multi-player version of minimax displays game-tree pathology”(AIJ 1993)中展示,参见 https://www.sciencedirect.com/science/article/pii/000437029390108N。 - Prof.Chaos
+1 但是你的回答在关于alpha-beta剪枝方面有点误导性。正如你提供的论文所说:alpha-beta对于多人(n>2)游戏并不高效,因为只能进行浅层剪枝。 - SaPropper
好吧,我没有说它很有效率。 :) (我甚至不知道。)如果你认为这很重要,我/我们可以添加该注释。(我认为这并不重要,但这只是我的观点。) - Prof.Chaos
6
对于这个问题,你不能再使用极小极大算法。除非你将最大化自己的利润和最小化对手利润总和这两个目标结合起来。但是这个方法很难实现。
更好的方法是创建能够在战略层面上学习需要做什么的算法。将游戏转化为一个双人对抗的形式:我vs.其他人,然后从这里开始。
- Mihai Maruseac
3
感谢您的反馈。目前还不能点赞 : )。我正在考虑扩展A*算法的思路。 - AlphaWolf
嘿,你正在玩编程游戏对吧?你把它应用到了Tron Battle上了吗? - DollarAkshay
不是 :) 我的意思是,我在那里,但我还没有应用它。 - Mihai Maruseac
-1
如何处理具有多个最小化代理的最小化函数是运行一个具有所有代理相同深度的最小化函数。一旦所有最小化代理都经过了,您可以在最后一个最小化代理上运行最大化函数。
# HOW YOU HANDLE THE MINIMIZING FUNCTION - If this pseudocode helps make better sense out of this.
scores = []
if agent == end_of_minimizing_agents: # last minimizing agent
for actions in legal_actions:
depth_reduced = depth-1
scores.append(max(successor_state, depth_reduced))
else:
for actions in legal_actions:
scores.append(min(successor_state, depth))
bestScore = min(scores)
return bestScore
- Flyn Sequeira
网页内容由stack overflow 提供, 点击上面的可以查看英文原文,
原文链接
原文链接