我一直在寻找一种先进的莱文斯坦距离算法,到目前为止,我发现最好的算法是O(n*m),其中n和m是两个字符串的长度。 算法之所以处于这个级别,是因为空间而不是时间,需要创建一个类似于以下矩阵的两个字符串的矩阵:
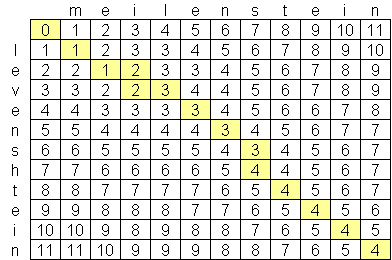
我一直在寻找一种先进的莱文斯坦距离算法,到目前为止,我发现最好的算法是O(n*m),其中n和m是两个字符串的长度。 算法之所以处于这个级别,是因为空间而不是时间,需要创建一个类似于以下矩阵的两个字符串的矩阵:
你是否对减少时间复杂度或空间复杂度感兴趣?平均时间复杂度可以降低到O(n + d^2),其中n是较长字符串的长度,d是编辑距离。如果你只关心编辑距离而不关心重构编辑序列,则只需要保留矩阵的最后两行即可,这样的顺序为n。
如果你能够接受近似值,则有多项式对数逼近。
对于O(n + d^2)算法,请查找Ukkonen优化或其增强版本Enhanced Ukkonen。我所知道的最好的逼近方法是由Andoni,Krauthgamer,Onak提出的。
如果你只需要阈值函数,例如测试距离是否小于某个阈值,你可以通过仅计算数组中主对角线两侧的n个值来减少时间和空间复杂度。你还可以使用Levenshtein自动机在O(n)时间内评估许多单词与单个基础单词的相似度,并且自动机的构建也可以在O(m)时间内完成。
请参考维基百科——他们提供了一些改进此算法以更好地减少空间复杂度的想法:
引用:
我们可以使算法适应更小的空间,即O(m)而不是O(mn),因为它只需要在任何时候存储前一行和当前行。
public static int optimalStringAlignmentDistance(String s1, String s2) {
if (s1.length() > s2.length()) {
return optimalStringAlignmentDistance(s2, s1);
}
// Initialize the table
int[][] dp = new int[s1.length()+1][s2.length()+1];
for (int i = 0; i <= s1.length(); i++) {
dp[i][0] = i;
}
for (int j = 0; j <= s2.length(); j++) {
dp[0][j] = j;
}
// Populate the table using dynamic programming
for (int i = 1; i <= s1.length(); i++) {
for (int j = i; j <= s2.length(); j++) {
if (s1.charAt(i-1) == s2.charAt(j-1)) {
dp[i][j] = dp[i-1][j-1];
} else {
int topMin = Math.min(dp[i-1][j-1], dp[i-1][j]);
if (j == i) {
// dp[i][j-1] is not in this triangular portion
dp[i][j] = 1 + topMin;
} else {
dp[i][j] = 1 + Math.min(topMin, dp[i][j-1]);
}
}
}
}
// Return the edit distance
return dp[s1.length()][s2.length()];
}
我发现另一种声称是O(max(m, n))的优化方法:
http://en.wikibooks.org/wiki/Algorithm_Implementation/Strings/Levenshtein_distance#C
(第二个C语言实现)