找到一个标准化的数据框,移除用于分组的列,因此它不能在后续的groupby操作中使用。例如(编辑:已更新):
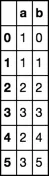
df = pd.DataFrame({'a':[1, 1 , 2, 3, 2, 3], 'b':[0, 1, 2, 3, 4, 5]})
a b
0 1 0
1 1 1
2 2 2
3 3 3
4 2 4
5 3 5
df.groupby('a').transform(lambda x: x)
b
0 0
1 1
2 2
3 3
4 4
5 5
现在,对于大多数组合操作而言,“缺失”的列会成为一个新的索引(可以使用reset_index进行调整,或设置as_index=False),但是当使用transform时,该列会消失,留下原始索引和一个没有关键字的新数据集。
编辑:下面是我想要做到的一行代码:
df.groupby('a').transform(lambda x: x+1).groupby('a').mean()
KeyError 'a'
更新: 看起来reset_index/as_index仅适用于将每个组缩减为单行的函数。 从答案中似乎有一些选项。
df.assign(new=df.groupby('a').transform('sum'))? - MaxU - stand with Ukrainedf.groupby('a').apply(lambda x: (x.b+1).mean()): - MaxU - stand with Ukraine