您可以使用以下三种方式进行表达式求值: 1) pd.eval(), 2) df.query(),或者3) df.eval()。下面将讨论它们的不同特点和功能。
示例将涉及这些数据框(除非另有说明)。
np.random.seed(0)
df1 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df2 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df3 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
df4 = pd.DataFrame(np.random.choice(10, (5, 4)), columns=list('ABCD'))
1) pandas.eval
这是 pandas 文档应该包含的“缺失手册”。
注意:在这里讨论的三个函数中,pd.eval 是最重要的。 df.eval 和 df.query 在后台调用
pd.eval。这三个函数的行为和使用方式基本一致,但有一些细微的语义变化,稍后会进行说明。本节将介绍所有三个函数都具有的功能,包括(但不限于)允许的语法、运算优先级规则和关键字参数。
pd.eval 可以评估由变量和/或文字组成的算术表达式。这些表达式必须作为字符串传递。因此,回答上述问题,可以执行以下操作:
x = 5
pd.eval("df1.A + (df1.B * x)")
需要注意以下几点:
- 整个表达式都是一个字符串
df1、df2和x指的是全局命名空间中的变量,在解析表达式时,eval会引用这些变量- 可以使用属性访问器索引来访问特定的列。您也可以使用
"df1['A'] + (df1['B'] * x)"来实现同样的效果。
在下面解释target=...属性的部分中,我将详细讨论重新赋值的具体问题。但现在,以下是更多有效操作的简单示例:pd.eval:
pd.eval("df1.A + df2.A") # Valid, returns a pd.Series object
pd.eval("abs(df1) ** .5") # Valid, returns a pd.DataFrame object
......等等。条件表达式也可以以相同的方式进行支持。以下语句都是有效的表达式,并将由引擎进行评估。
pd.eval("df1 > df2")
pd.eval("df1 > 5")
pd.eval("df1 < df2 and df3 < df4")
pd.eval("df1 in [1, 2, 3]")
pd.eval("1 < 2 < 3")
在文档中可以找到详细支持的特性和语法列表。总结如下:
- 算术操作(除了左移(
<<)和右移(>>)运算符),例如df + 2 * pi / s ** 4 % 42 - the_golden_ratio
- 比较操作,包括链式比较,例如
2 < df < df2
- 布尔操作,例如
df < df2 and df3 < df4或者not df_bool
list和tuple字面量,例如[1, 2]或(1, 2)
- 属性访问,例如
df.a
- 下标表达式,例如
df[0]
- 简单变量求值,例如
pd.eval('df')(这不太有用)
- 数学函数:sin、cos、exp、log、expm1、log1p、sqrt、sinh、cosh、tanh、arcsin、arccos、arctan、arccosh、arcsinh、arctanh、abs和
arctan2。
文档的这一部分还指定了不支持的语法规则,包括set/dict字面量、if-else语句、循环和解析式以及生成器表达式。
从列表可以看出,您还可以传递涉及索引的表达式,例如
pd.eval('df1.A * (df1.index > 1)')
1a) 解析器选择: parser=... 参数
pd.eval支持两种不同的解析器选项来解析表达式字符串生成语法树:pandas和python。两者之间的主要区别在于优先级规则略有不同。
使用默认解析器pandas时,重载的按位运算符&和|将实现基于pandas对象的矢量化AND和OR操作,其运算符优先级与and和or相同。所以,
pd.eval("(df1 > df2) & (df3 < df4)")
与之前相同
pd.eval("df1 > df2 & df3 < df4")
# pd.eval("df1 > df2 & df3 < df4", parser='pandas')
同时也与之相同
pd.eval("df1 > df2 and df3 < df4")
在这里,括号是必要的。要按照传统方式完成这个操作,需要使用括号来覆盖按位运算符的高优先级:
(df1 > df2) & (df3 < df4)
没有这个,我们最终会得到
df1 > df2 & df3 < df4
ValueError: The truth value of a DataFrame is ambiguous. Use a.empty, a.bool(), a.item(), a.any() or a.all().
如果您想在评估字符串时与Python的实际运算符优先级规则保持一致,请使用parser = 'python'。
pd.eval("(df1 > df2) & (df3 < df4)", parser='python')
两种解析器之间的另一个区别是使用 'pandas' 解析器时,列表和元组节点中 == 和 != 运算符的语义与 in 和 not in 的语义类似。例如:
pd.eval("df1 == [1, 2, 3]")
是合法的,并将具有与原来相同的语义
pd.eval("df1 in [1, 2, 3]")
另一方面,pd.eval("df1 == [1, 2, 3]", parser='python') 将会抛出一个 NotImplementedError 错误。
1b) 后端选择: engine=... 参数
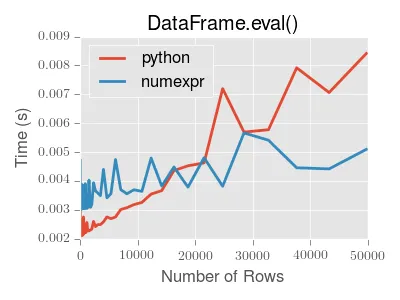
有两个选项 - numexpr(默认)和 python。 numexpr 选项使用了经过优化的性能后端numexpr。
使用 Python 后端,您的表达式类似于将表达式传递给 Python 的 eval 函数进行评估。您可以在表达式中执行更多的操作,例如字符串操作。
df = pd.DataFrame({'A': ['abc', 'def', 'abacus']})
pd.eval('df.A.str.contains("ab")', engine='python')
0 True
1 False
2 True
Name: A, dtype: bool
很不幸,此方法与numexpr引擎相比没有性能优势,并且几乎没有安全措施来确保不会评估危险表达式,因此使用时需自担风险!通常不建议将此选项更改为'python',除非您知道自己在做什么。
1c)local_dict和global_dict参数
有时候,提供在表达式中使用但当前未定义在命名空间中的变量值是有用的。您可以将字典传递给local_dict。
例如:
pd.eval("df1 > thresh")
UndefinedVariableError: name 'thresh' is not defined
这个失败是因为thresh没有定义。然而,这个可以工作:
pd.eval("df1 > thresh", local_dict={'thresh': 10})
当你需要从字典中提供变量时,这将非常有用。 或者,使用Python引擎,您可以简单地执行以下操作:
mydict = {'thresh': 5}
pd.eval('df1 > mydict["thresh"]', engine='python')
但是这种方法可能比使用'numexpr'引擎并将字典传递给local_dict或global_dict要慢得多。希望这可以为使用这些参数提供令人信服的论据。
1d) target(+inplace)参数和赋值表达式
通常不需要这样做,因为通常有更简单的方法可以完成此操作,但您可以将pd.eval的结果分配给实现__getitem__(例如字典和数据帧)的对象。
考虑问题中的示例
x = 5
df2['D'] = df1['A'] + (df1['B'] * x)
将列“D”分配给df2,我们可以执行:pd.eval('D = df1.A + (df1.B * x)', target=df2)
A B C D
0 5 9 8 5
1 4 3 0 52
2 5 0 2 22
3 8 1 3 48
4 3 7 0 42
这不是对 df2 的原地修改(但可以进行...继续阅读)。考虑另一个例子:
pd.eval('df1.A + df2.A')
0 10
1 11
2 7
3 16
4 10
dtype: int32
如果你想要(例如)将此分配回 DataFrame,可以使用 target 参数,如下所示:
df = pd.DataFrame(columns=list('FBGH'), index=df1.index)
df
F B G H
0 NaN NaN NaN NaN
1 NaN NaN NaN NaN
2 NaN NaN NaN NaN
3 NaN NaN NaN NaN
4 NaN NaN NaN NaN
df = pd.eval('B = df1.A + df2.A', target=df)
# Similar to
# df = df.assign(B=pd.eval('df1.A + df2.A'))
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
如果您想在 df 上执行就地突变,请设置 inplace=True。pd.eval('B = df1.A + df2.A', target=df, inplace=True)
# Similar to
# df['B'] = pd.eval('df1.A + df2.A')
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
如果未指定目标设置 inplace,会引发 ValueError。
虽然可以玩弄 target 参数,但很少需要使用它。
如果您想在 df.eval 中执行此操作,您将使用涉及赋值的表达式:
df = df.eval("B = @df1.A + @df2.A")
df
F B G H
0 NaN 10 NaN NaN
1 NaN 11 NaN NaN
2 NaN 7 NaN NaN
3 NaN 16 NaN NaN
4 NaN 10 NaN NaN
注意
pd.eval 的一个意外用途是以与 ast.literal_eval 非常相似的方式解析文本字符串:
pd.eval("[1, 2, 3]")
array([1, 2, 3], dtype=object)
还可以使用 'python' 引擎解析嵌套列表:
pd.eval("[[1, 2, 3], [4, 5], [10]]", engine='python')
[[1, 2, 3], [4, 5], [10]]
还有字符串列表:
pd.eval(["[1, 2, 3]", "[4, 5]", "[10]"], engine='python')
[[1, 2, 3], [4, 5], [10]]
然而,问题是列表长度大于100:
pd.eval(["[1]"] * 100, engine='python')
pd.eval(["[1]"] * 101, engine='python')
AttributeError: 'PandasExprVisitor' object has no attribute 'visit_Ellipsis'
更多关于此错误、原因、解决方法和解决方案的信息可以在这里找到。
如上所述,df.eval在幕后会调用pd.eval,并做一些参数的摆放。在v0.23源代码中有所显示。
def eval(self, expr, inplace=False, **kwargs):
from pandas.core.computation.eval import eval as _eval
inplace = validate_bool_kwarg(inplace, 'inplace')
resolvers = kwargs.pop('resolvers', None)
kwargs['level'] = kwargs.pop('level', 0) + 1
if resolvers is None:
index_resolvers = self._get_index_resolvers()
resolvers = dict(self.iteritems()), index_resolvers
if 'target' not in kwargs:
kwargs['target'] = self
kwargs['resolvers'] = kwargs.get('resolvers', ()) + tuple(resolvers)
return <b>_eval(expr, inplace=inplace, **kwargs)</b>
eval创建参数,进行少量验证,并将参数传递给pd.eval。更多信息请参见:When to use DataFrame.eval() versus pandas.eval() or Python eval()
2a) 用法差异
2a1) 与DataFrames表达式相比的Series表达式
对于整个数据框架相关的动态查询,应优先选择pd.eval。例如,当您调用df1.eval或df2.eval时,没有简单的方法来指定等效于pd.eval("df1 + df2")的表达式。
2a2) 指定列名
另一个主要区别是如何访问列。例如,在df1中添加两列“A”和“B”,您需要使用以下表达式调用pd.eval:
pd.eval("df1.A + df1.B")
使用df.eval,您只需要提供列名称:
df1.eval("A + B")
在 df1 的上下文中,“A”和“B”明显是列名。
您还可以使用 index 引用索引和列(除非索引有名称,否则应使用名称)。
df1.eval("A + index")
更一般地,对于任何具有1个或多个级别的索引的DataFrame,可以使用变量"ilevel_k"来表示表达式中索引的第k个级别,“ilevel_k”代表“在级别k处的索引”。也就是说,上面的表达式可以写成df1.eval("A + ilevel_0")。
这些规则也适用于df.query。
2a3) 访问本地/全局名称空间中的变量
表达式中提供的变量必须在前面加上“@”符号,以避免与列名混淆。
A = 5
df1.eval("A > @A")
对于query,同样适用。
显然,您的列名必须遵循Python中有效标识符命名的规则,以便在eval内部访问。有关命名标识符的规则,请参见此处。
2a4)多行查询和赋值
鲜为人知的是,eval支持处理赋值的多行表达式(而query则不支持)。例如,为了在df1中基于某些列进行算术运算并创建两个新列"E"和"F",以及基于先前创建的"E"和"F"创建第三个列"G",我们可以这样做:
df1.eval("""
E = A + B
F = @df2.A + @df2.B
G = E >= F
""")
A B C D E F G
0 5 0 3 3 5 14 False
1 7 9 3 5 16 7 True
2 2 4 7 6 6 5 True
3 8 8 1 6 16 9 True
4 7 7 8 1 14 10 True
3) eval vs query
df.query可被视为使用pd.eval作为子例程的函数。通常,query(顾名思义)用于评估条件表达式(即结果为True / False值的表达式)并返回与True结果相对应的行。然后将表达式的结果传递给loc(在大多数情况下)以返回满足表达式的行。根据文档:
首先对此表达式的计算结果进行传递至DataFrame.loc,如果由于多维键(例如DataFrame)而失败,则结果将传递给DataFrame.__getitem__()。
该方法使用顶级pandas.eval()函数来评估传递的查询。
就相似性而言,query和df.eval在它们访问列名和变量方面都是相似的。
这两者之间的关键区别,如上所述,是它们处理表达式结果的方式。当您实际通过这两个函数运行表达式时,这一点就变得明显了。例如,请考虑以下内容:
df1.A
0 5
1 7
2 2
3 8
4 7
Name: A, dtype: int32
df1.B
0 9
1 3
2 0
3 1
4 7
Name: B, dtype: int32
要获取在df1中,所有“A” >= “B”的行,我们可以用以下方式使用eval:
m = df1.eval("A >= B")
m
0 True
1 False
2 False
3 True
4 True
dtype: bool
m代表通过计算表达式“A >= B”生成的中间结果。接下来我们使用该掩码来过滤df1:
df1[m]
A B C D
0 5 0 3 3
3 8 8 1 6
4 7 7 8 1
然而,使用 query,中间结果“m”直接传递给 loc,所以使用 query,您只需要执行以下操作:
df1.query("A >= B")
A B C D
0 5 0 3 3
3 8 8 1 6
4 7 7 8 1
就性能而言,它完全相同。
df1_big = pd.concat([df1] * 100000, ignore_index=True)
14.7 ms ± 33.9 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
14.7 ms ± 24.3 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
但后者更为简洁,能够在一步中完成相同的操作。
请注意,您还可以使用query执行奇怪的操作,例如(返回所有由df1.index索引的行)。
df1.query("index")
A B C D
0 5 0 3 3
1 7 9 3 5
2 2 4 7 6
3 8 8 1 6
4 7 7 8 1
但是不要这样做。
底线: 当基于条件表达式查询或过滤行时,请使用query。
pandas.MultiIndex写一个类似的东西? - tel