我想创建一个子查询,作为单列结果生成数字列表,类似于 MindLoggedOut此处所做的, 但不使用
这将每行返回一个数字,速度相当快(比我迄今使用的字符串分割方法快20倍,类似于这些similar to these)。我是通过SQL Server CPU时间来测量20倍的加速效果的,其中
现在,如果我将
差异消失了(计划)。所以至少我有一个解决方法...但我想理解它。
@x xml变量,以便可以将其附加到WHERE表达式作为纯字符串(子查询),而不使用sql参数。问题在于参数(或变量)的替换使查询运行慢了5000倍,我不明白为什么。是什么导致了这个巨大的差异?/* Create a minimalistic xml like <b><a>78</a><a>91</a>...</b> */
DECLARE @p_str VARCHAR(MAX) =
'78 91 01 12 34 56 78 91 01 12 34 56 78 91 01 12 34 56';
DECLARE @p_xml XML = CONVERT(XML,
'<b><a>'+REPLACE(@p_str,' ','</a><a>')+'</a></b>'
);
SELECT a.value('(child::text())[1]','INT')
FROM (VALUES (@p_xml)) AS t(x)
CROSS APPLY x.nodes('//a') AS x(a);
这将每行返回一个数字,速度相当快(比我迄今使用的字符串分割方法快20倍,类似于这些similar to these)。我是通过SQL Server CPU时间来测量20倍的加速效果的,其中
@p_str包含3000个数字。现在,如果我将
@p_xml的定义内联到查询中:SELECT a.value('(child::text())[1]','INT')
FROM (VALUES (CONVERT(XML,
'<b><a>'+REPLACE(@p_str,' ','</a><a>')+'</a></b>'
))) AS t(x)
CROSS APPLY x.nodes('//a') AS x(a);
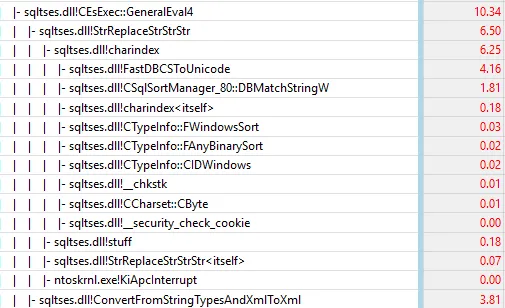
当@p_str包含数千个数字时,它会变得慢5000倍。查看查询计划,我找不到原因。
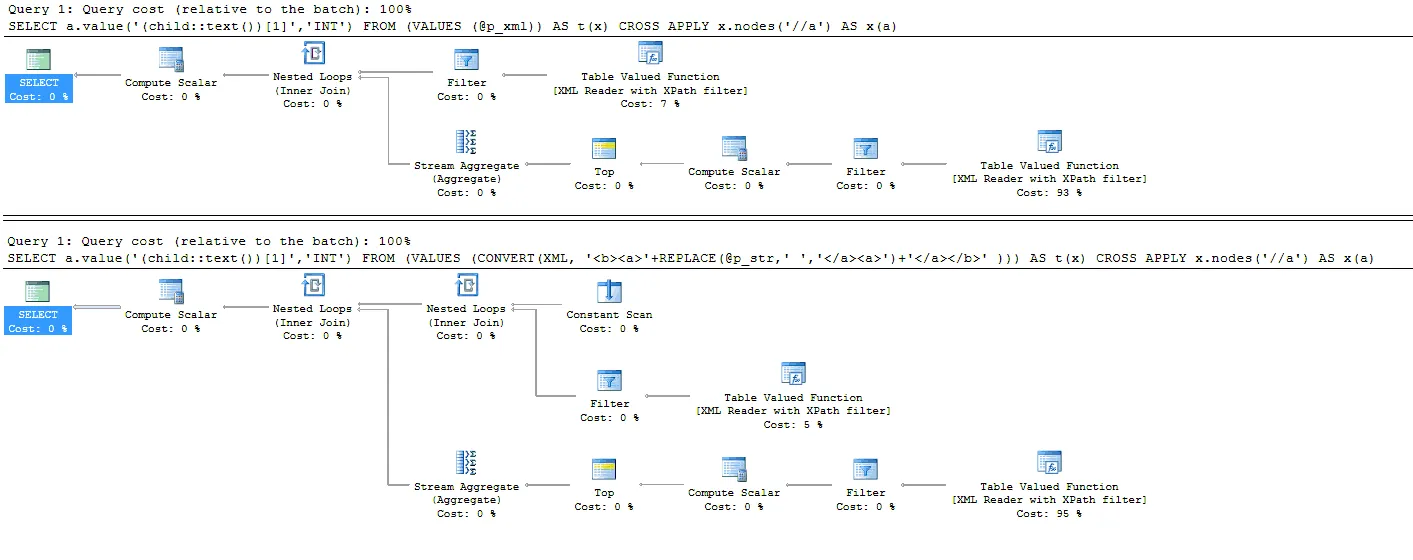 第一个查询的计划(…VALUES(@p_xml)…)和第二个查询的计划(…VALUES(CONVERT(XML,'...'))…)
第一个查询的计划(…VALUES(@p_xml)…)和第二个查询的计划(…VALUES(CONVERT(XML,'...'))…)
有人能解释一下吗?
更新
很明显,第一个查询的计划并没有包括@p_xml = CONVERT(XML, ...REPLACE(...)... )这个赋值语句的成本,但是这个成本并不是可以解释整个脚本执行时间(当@p_str很大时)46毫秒和234秒之间巨大差异的罪魁祸首。这种差异是系统性(而非随机性)的,并且实际上在SqlAzure(S1层)中观察到了。此外,当我重写查询时:将CONVERT(XML,...)替换为用户定义的标量函数时:
SELECT a.value('(child::text())[1]','INT')
FROM (VALUES (dbo.MyConvertToXmlFunc(
'<b><a>'+REPLACE(@p_str,' ','</a><a>')+'</a></b>'
))) AS t(x)
CROSS APPLY x.nodes('//a') AS x(a);
其中dbo.MyConvertToXmlFunc()是:
CREATE FUNCTION dbo.MyConvertToXmlFunc(@p_str NVARCHAR(MAX))
RETURNS XML BEGIN
RETURN CONVERT(XML, @p_str);
END;
差异消失了(计划)。所以至少我有一个解决方法...但我想理解它。
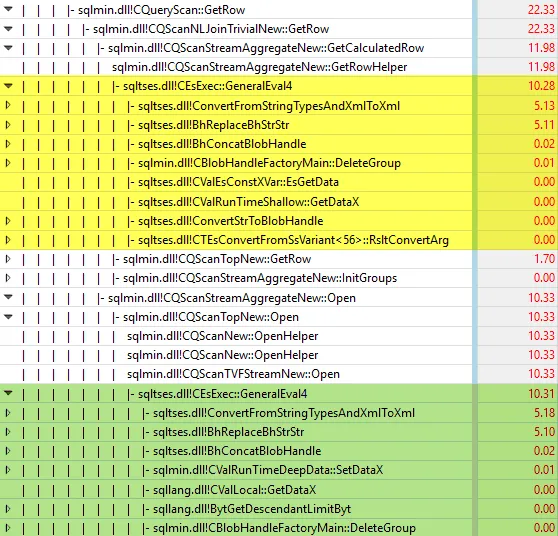
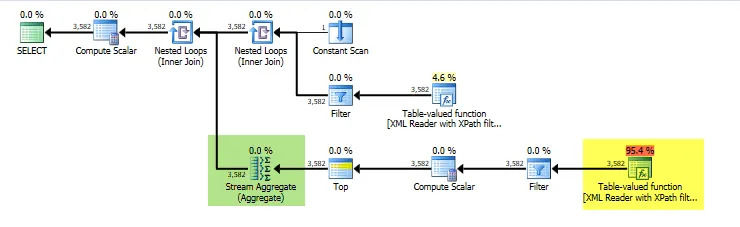
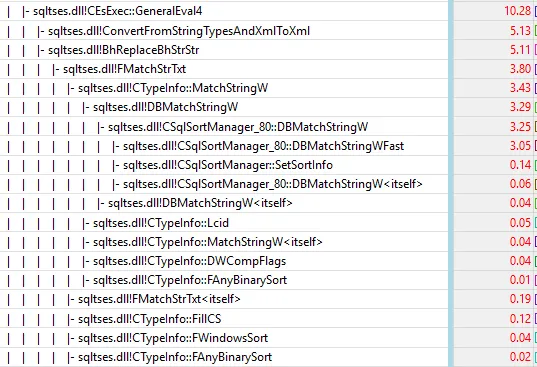
@p_xml的赋值(从字符串到XML的相关转换)不会在执行计划中显示,因此你并没有进行类似于类比的比较。 - JohnLBevan