tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 会输出来自于正态分布的随机值。
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 会输出来自于截断正态分布的随机值。
我尝试谷歌搜索“截断正态分布”,但是并没有理解很多内容。
tf.random_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 会输出来自于正态分布的随机值。
tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 会输出来自于截断正态分布的随机值。
我尝试谷歌搜索“截断正态分布”,但是并没有理解很多内容。
文档已经说明了一切:
从指定的均值和标准差的正态分布中抽取值,舍弃并重新抽取任何距离均值超过两个标准差的样本。
可能最好通过绘制图形自行理解差异(%magic是因为我使用Jupyter Notebook):
import tensorflow as tf
import matplotlib.pyplot as plt
%matplotlib inline
n = 500000
A = tf.truncated_normal((n,))
B = tf.random_normal((n,))
with tf.Session() as sess:
a, b = sess.run([A, B])
现在
plt.hist(a, 100, (-4.2, 4.2));
plt.hist(b, 100, (-4.2, 4.2));
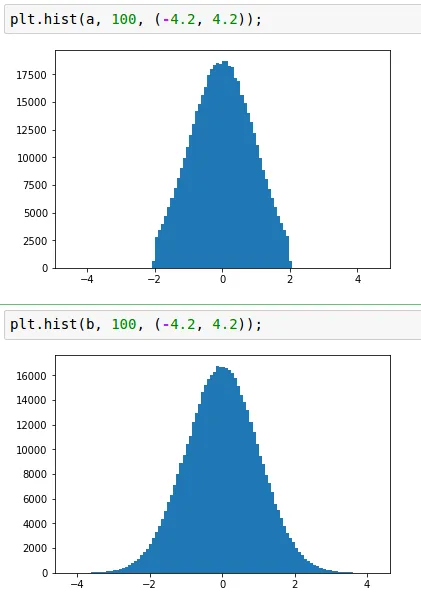
使用截断正态分布的目的是克服像sigmoid这样的函数饱和问题(当值太大/太小时,神经元停止学习)。
tf.truncated_normal()会从一个均值接近0且范围在-0.1到0.1之间的正态分布中随机选取数字。它被称为截断的是因为你截掉了正态分布的尾巴。
tf.random_normal()会从一个均值接近0且范围在-2到2之间的正态分布中随机选取数字。
在实践中,机器学习通常希望权重接近于0。
tf.truncated_normal() 的API文档描述了以下功能:
从截断正态分布中输出随机值。
生成的值遵循指定均值和标准差的正态分布,但其绝对值大于均值 2 个标准差的值将被丢弃并重新选择。