我从math.stackexchange.com转发这篇文章,因为我没有得到任何反馈,而且对我来说这是一个时间紧迫的问题。
我的问题涉及支持向量机中的超平面线性可分性。
根据维基百科:
正式地说,支持向量机在高维或无限维空间中构建一个超平面或一组超平面,可用于分类、回归或其他任务。直观地说,通过具有任何类别的最近训练数据点(所谓的函数间隔)的距离最大的超平面来实现良好的分离,因为通常情况下,边界越大,分类器的泛化误差就越低。
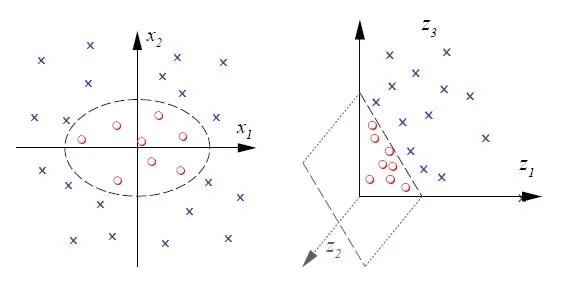
对我来说,通过超平面进行类别的线性分离是有直观意义的。我认为我理解了二维几何中的线性可分性。然而,我正在使用一种流行的SVM库(libSVM)实现SVM时,当我玩弄数字时,我无法理解SVM如何在类别之间创建曲线,或者如何在n维空间V中,如果一个超平面是维数为n-1的“平坦”子集,或者在二维空间中 - 是一条1D线,则可以围绕类别1中心点内部的圆形曲线中包含被类别2包围的点。
这就是我的意思:
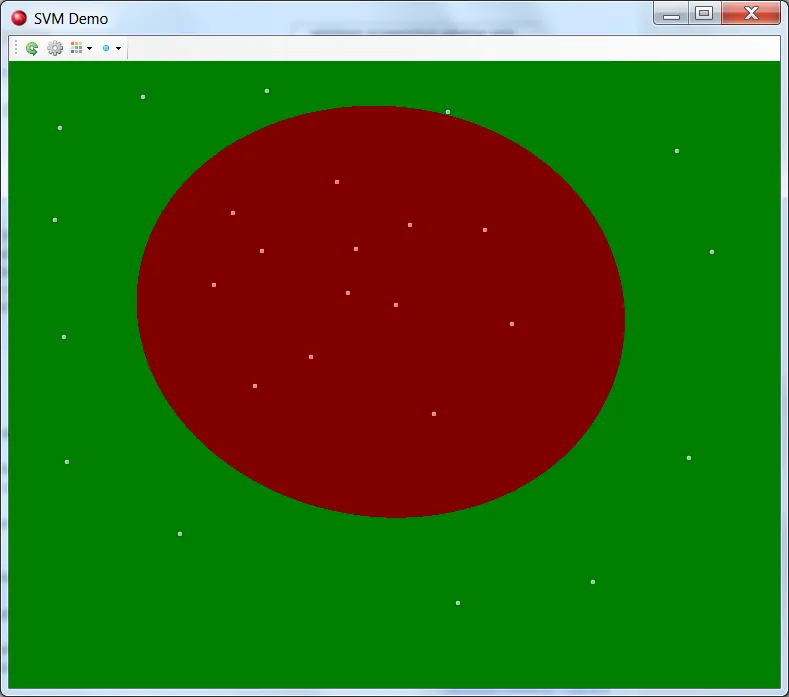
这个示例应用程序可以从这里下载。
编辑:
感谢您详尽的回答。因此,SVM可以通过使用核函数很好地分离奇怪的数据。在将数据发送到SVM之前,将其线性化是否有帮助?例如,我的一个输入特征(数值)具有拐点(例如0),在该拐点处它完美地适合于类别1,但在零以上和以下,则适合于类别2。现在,因为我知道这一点,将该特征的绝对值发送给SVM是否有助于分类?