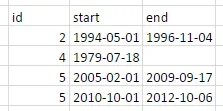
我的数据看起来像这样:
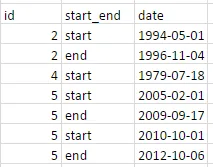
我正在尝试使它看起来像这样:
df <-
structure(list(id = c(2L, 2L, 4L, 5L, 5L, 5L, 5L), start_end = structure(c(2L,
1L, 2L, 2L, 1L, 2L, 1L), .Label = c("end", "start"), class = "factor"),
date = structure(c(6L, 7L, 3L, 8L, 9L, 10L, 11L), .Label = c("1979-01-03",
"1979-06-21", "1979-07-18", "1989-09-12", "1991-01-04", "1994-05-01",
"1996-11-04", "2005-02-01", "2009-09-17", "2010-10-01", "2012-10-06"
), class = "factor")), .Names = c("id", "start_end", "date"
), row.names = c(3L, 4L, 7L, 8L, 9L, 10L, 11L), class = "data.frame")
我尝试过的:
data.table::dcast( df, formula = id ~ start_end, value.var = "date", drop = FALSE ) # does not work because it summarises the data
tidyr::spread( df, start_end, date ) # does not work because of duplicate values
df$id2 <- 1:nrow(df)
tidyr::spread( df, start_end, date ) # does not work because the dataset now has too many rows.
这些问题并不能回答我的问题: 使用spread处理具有重复标识符的行(因为它们只是总结) R中处理具有重复数据框的spread函数(因为它们将值粘贴在一起) 使用“登录”“注销”时间在R中重塑数据(因为不是特别要求/使用tidyverse和链接来回答)
reshape2和dplyr:df %>% group_by(id, start_end) %>% arrange(date) %>% mutate(sequence=1:n()) %>% dcast(id + sequence ~ start_end, value="date")。 - eipi10