首先,这是我的数据的一部分(121315*4):
LONGITUDE LATITUDE NUM_PICKUPS TOTAL_REVENUE
1 121.6177 38.9124 21 337.0
2 121.8069 39.0210 16 454.7
3 121.5723 38.9645 38 696.9
4 121.6423 38.9258 622 13609.7
5 121.5647 38.9129 116 2016.7
6 121.6429 38.8846 120 2417.3
7 121.5852 38.9279 117 1975.0
8 121.6616 38.9189 94 1712.4
9 121.5812 38.9828 50 981.6
10 121.6411 38.9255 225 4696.2
看到这里,第一列和第二列是经度和纬度。
mydata[1,3]=21表示在(121.6177, 38.9124)这个地方有21次乘车。
接着,我按照NUM_PICKUPS的降序重新排列了mydata:
LONGITUDE LATITUDE NUM_PICKUPS TOTAL_REVENUE
121.6019 39.0181 14243 514716
121.5382 38.9609 13244 443754.7
121.5381 38.9609 9645 325056
121.5382 38.9608 8846 294345.6
121.602 39.0181 6556 232254.5
121.5383 38.9609 6152 208967.6
121.5383 38.9608 6014 207677.8
121.5381 38.9608 5544 185398.3
121.6018 39.018 4546 167662.1
121.5382 38.9607 4260 143088.9
121.5827 38.8948 4133 72202.8
121.6303 38.9183 3837 67683.6
121.5966 38.9665 3747 56378.7
以下是我的数据概述:
summary(mydata)
LONGITUDE LATITUDE NUM_PICKUPS TOTAL_REVENUE
Min. :121.1 Min. :38.76 Min. : 10.00 Min. : 92.9
1st Qu.:121.6 1st Qu.:38.91 1st Qu.: 15.00 1st Qu.: 289.7
Median :121.6 Median :38.92 Median : 27.00 Median : 515.1
Mean :121.6 Mean :38.93 Mean : 57.03 Mean : 1067.6
3rd Qu.:121.6 3rd Qu.:38.96 3rd Qu.: 59.00 3rd Qu.: 1089.5
Max. :122.0 Max. :39.32 Max. :14243.00 Max. :514716.0
现在,我想绘制一个由
NUM_PICKUPS着色的地图,请看我的代码。g1 <- ggplot() + geom_point(data = mydata,aes(x = LONGITUDE,y = LATITUDE,color=NUM_PICKUPS))
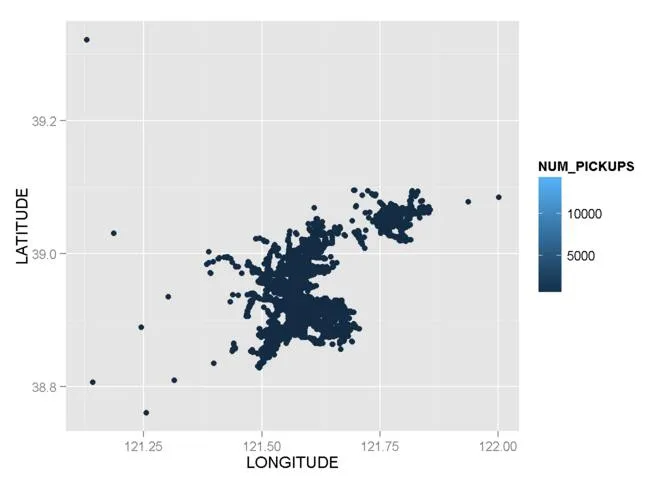
是的,代码和图形都没问题,但看看颜色,很难辨别哪里是高num_pickups的地方?哪里是低的?
我尝试使用scale_colour_gradient()修改我的代码:
g1 + scale_colour_gradient(low = "red",high = "white")
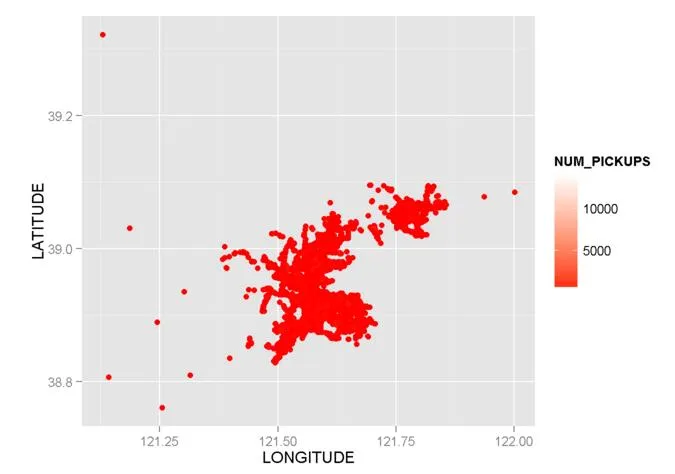
看这张图片,颜色也很难分类。
第三次尝试:这次我加入了alpha=I(1/100)和breaks()参数:
g1 <- ggplot() + geom_point(data = mydata,aes(x = LONGITUDE,y = LATITUDE,color=NUM_PICKUPS),alpha=I(1/100))
g1 + scale_colour_gradient(low = "red",high = "white", breaks=c(0,2000,4000))
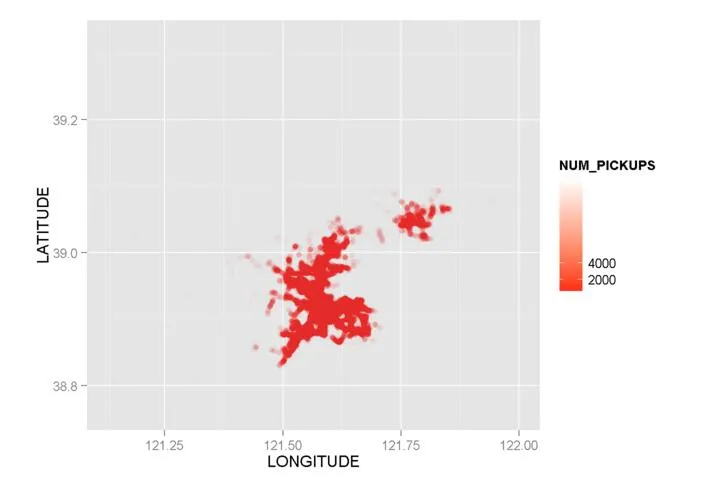
但是还是无能为力!
第四次尝试:
ggplot(data = mydata, aes(x = LONGITUDE,y = LATITUDE, color = NUM_PICKUPS)) + geom_point() + scale_colour_gradient(limits = c(0, 60))
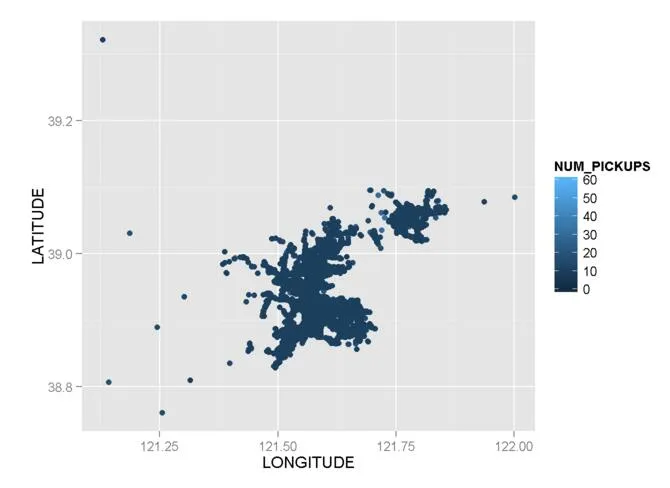
第五次尝试: 根据三年前的帖子ggplot2 Color Scale Over Affected by Outliers,我再次尝试修改我的代码:
mydata$NUM_PICKUPS1 <- "> 2000"
mydata$NUM_PICKUPS1[mydata$NUM_PICKUPS <= 2000] <- NA
g2 <- ggplot() + geom_point(data = subset(mydata,NUM_PICKUPS <= 2000),
aes(x = LONGITUDE,y = LATITUDE,color=NUM_PICKUPS),size=2) + geom_point(data = subset(mydata,NUM_PICKUPS > 2000),aes(x = LONGITUDE,y = LATITUDE,fill=NUM_PICKUPS1))
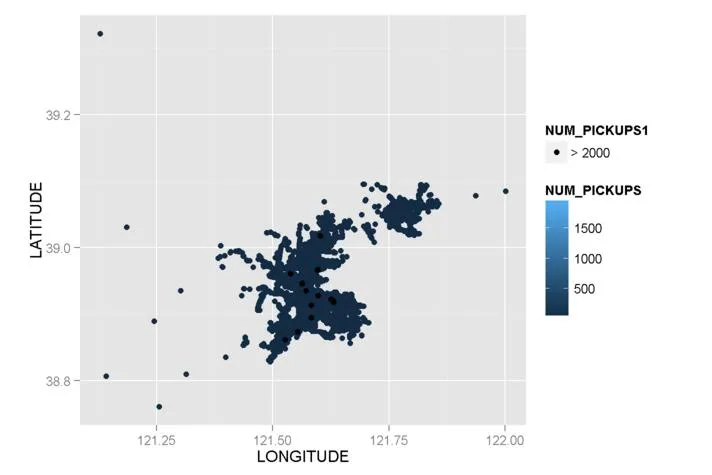
有些异常值确实发生了变化,但是颜色的比例尺依然很难区分!
因此,我的问题是如何修改代码,使NUM_PICKUPS的颜色更容易识别?
NUM_PICKUPS中是否有异常值?能否发布summary(mydata$NUM_PICKUPS)的结果?看起来可能存在一个非常大的值,导致比例尺需要扩展以适应它。 - Philscale_colour_gradientn和rescale参数来增加您的颜色比例尺的某个范围的分辨率,具体描述请参见此处(类似的描述也适用于scale_fill_gradientn,请参见此处)。 - Henrikscale_colour_gradient(low = "red",high = "white", breaks=c(2000,4000,6000))来强制比例尺根据数据分布进行调整 _(根据你的数据调整断点)_。 - GPierre