问题
假设我有两个区间的集合,命名为A和B。如何以最高效的时间和内存找到它们之间的差异(相对补集)?
下面是一个示意图: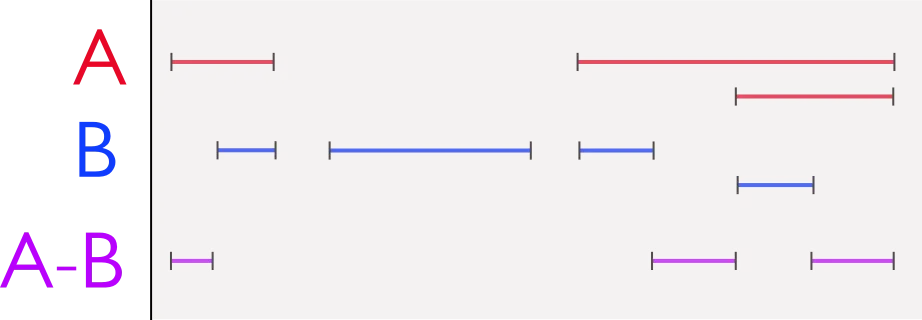
区间端点是整数(≤ 2128-1),它们总是2n长,并且在m×2n的网格上对齐(因此您可以用它们创建二叉树)。
输入数据中的区间可能会重叠,但这不会影响输出结果(平坦化后的结果相同)。
问题在于两个集合都包含许多区间(多达100,000,000个),因此朴素的实现可能会很慢。
输入从两个文件读取,并按照某种方式排序,使得较小的子区间(如果重叠)紧随其父级以大小顺序出现。例如:
[0,7]
[0,3]
[4,7]
[4,5]
[8,15]
...
我尝试了什么?
到目前为止,我一直在开发一个生成二叉搜索树的实现,同时聚合两个集合中邻近的区间([0,3],[4,7] => [0,7]),然后遍历第二棵树并“挤出”同时存在于两个树中的区间(如果必要,将在第一个树中分割更大的区间)。
虽然对小集合似乎有效,但需要越来越多的RAM来保留树本身,更不用说需要完成从树中插入和删除所需的时间。
我想到既然区间预先排序,就可以使用某些动态算法,并在一次扫描中完成。但我不确定这是否可能。
那么,如何以高效的方式解决这个问题呢?
免责声明:这不是作业,而是我面临的实际问题的修改/概括。我正在使用C++进行编程,但我可以接受任何[命令式]语言的算法。