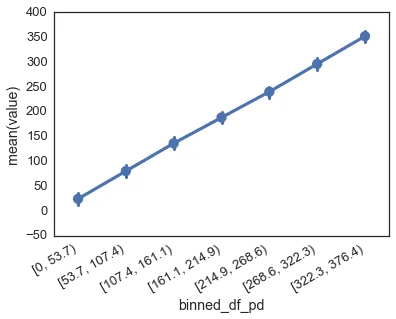
我的数据框中最小值为零。我试图使用 pandas.cut() 的 precision 和 include_lowest 参数,但是我无法得到由整数组成而不是浮点数的间隔,并且我也无法使最左侧的间隔停在零。
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
sns.set(style='white', font_scale=1.3)
df = pd.DataFrame(range(0,389,8)[:-1], columns=['value'])
df['binned_df_pd'] = pd.cut(df.value, bins=7, precision=0, include_lowest=True)
sns.pointplot(x='binned_df_pd', y='value', data=df)
plt.xticks(rotation=30, ha='right')
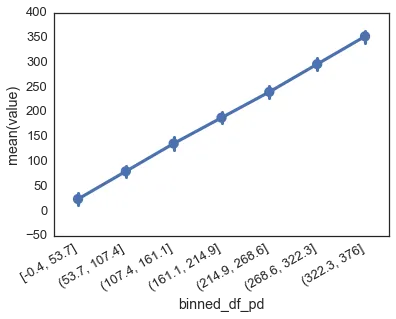
我尝试将precision设置为-1、0和1,但它们都输出一个小数。 pandas.cut()的帮助文件确实提到x-min和x-max值会扩展0.1%的x范围,但我认为也许include_lowest可以在某种程度上抑制这种行为。我目前的解决方法涉及导入numpy:
import numpy as np
bin_counts, edges = np.histogram(df.value, bins=7)
edges = [int(x) for x in edges]
df['binned_df_np'] = pd.cut(df.value, bins=edges, include_lowest=True)
sns.pointplot(x='binned_df_np', y='value', data=df)
plt.xticks(rotation=30, ha='right')
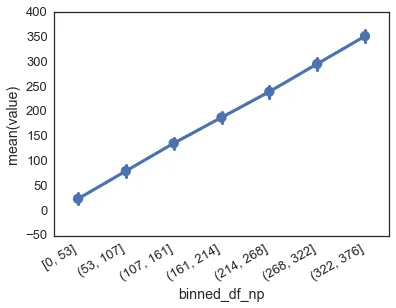
是否有一种方法可以直接使用 pandas.cut() 获得非负整数作为间隔边界,而不使用numpy?
编辑:我刚注意到指定 right=False 会使最低区间从-0.4移动到0。看来它优先于 include_lowest,因为改变后者与 right=False 的组合没有任何可见的效果。下面的区间仍然用一个小数点指定。