由于您关心效率,字符串操作是Pandas中常见的“陷阱”之一,因为虽然它们是矢量化的(可以一次性应用于整个Series),但这并不意味着它们比循环更有效率。这是一个例子,在这种情况下,循环实际上会比使用字符串访问器更快,后者往往更多地用于方便而非速度。
如果不确定,请确保在实际数据上计时函数,因为您认为笨拙缓慢的东西可能比看起来干净的东西更快!
我将提出一个非常基本的循环函数,我认为它将击败任何使用字符串访问器的方法。
def loopy(series):
return pd.Series(
(
el.zfill(9) if len(el) < 9 else el.zfill(20)
for el in series
),
name=series.name,
)
def cache_loopy(series, _len=len, _zfill=str.zfill):
return pd.Series(
(_zfill(el, 9 if _len(el) < 9 else 20) for el in series), name=series.name)
现在让我们使用Martijn提供的代码和simple_benchmark来检查时间。
函数
def loopy(series):
series.copy()
return pd.Series(
(
el.zfill(9) if len(el) < 9 else el.zfill(20)
for el in series
),
name=series.name,
)
def str_accessor(series):
target = series.copy()
mask = series.str.len() < 9
unmask = ~mask
target[mask] = target[mask].str.zfill(9)
target[unmask] = target[unmask].str.zfill(20)
return target
def np_where_str_accessor(series):
target = series.copy()
return np.where(target.str.len()<9,target.str.zfill(9),target.str.zfill(20))
def fill_zeros(x, _len=len, _zfill=str.zfill):
return _zfill(x, 9 if _len(x) < 9 else 20)
def apply_fill(series):
series = series.copy()
return series.apply(fill_zeros)
def cache_loopy(series, _len=len, _zfill=str.zfill):
series.copy()
return pd.Series(
(_zfill(el, 9 if _len(el) < 9 else 20) for el in series), name=series.name)
设置
import pandas as pd
import numpy as np
from random import choices, randrange
from simple_benchmark import benchmark
def randvalue(chars="0123456789", _c=choices, _r=randrange):
return "".join(_c(chars, k=randrange(5, 30))).lstrip("0")
fns = [loopy, str_accessor, np_where_str_accessor, apply_fill, cache_loopy]
args = { 2**i: pd.Series([randvalue() for _ in range(2**i)]) for i in range(14, 21)}
b = benchmark(fns, args, 'Series Length')
b.plot()
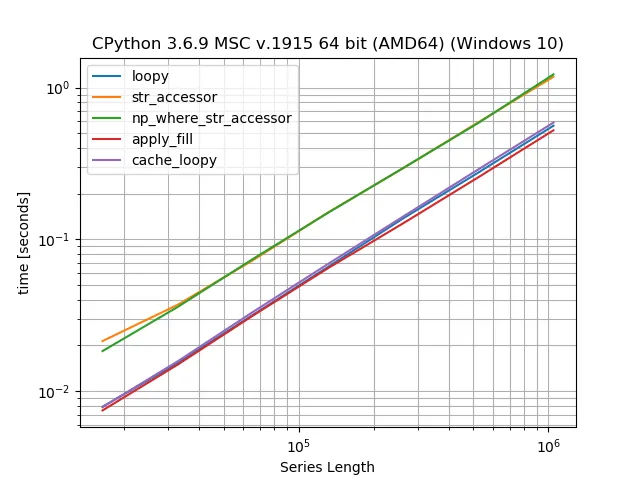
np.where()从这两组行中进行选择,长度为9的列被填充到长度为20。后者也是OP发布的代码中的缺陷。 - Martijn Pieters