我想创建一个Excel电子表格,并为每个可变量插入相同数量的行。理想的结果应该看起来像图片中的A列和B列。
到目前为止,我只能为1个名称(D列和E列)插入,不知道如何对其余部分进行适当的枚举。
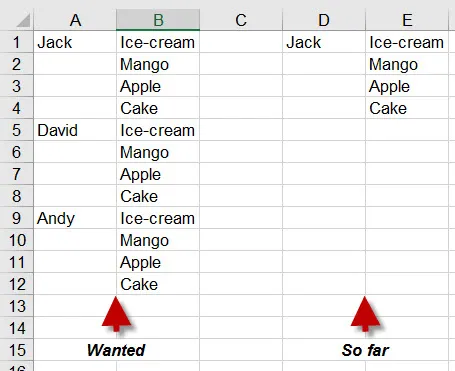
这是我所拥有的:
import xlwt, xlrd
import os
current_file = xlwt.Workbook()
write_table = current_file.add_sheet('Sheet1')
name_list = ["Jack", "David", "Andy"]
food_list = ["Ice-cream", "Mango", "Apple", "Cake"]
total_rows = len(name_list) * len(food_list) # how to use it?
write_table.write(0, 0, "Jack")
for row, food in enumerate(food_list):
write_table.write(row, 1, food)
current_file.save("c:\\name_food.xls")
我该如何做到普及化?谢谢。