我有两个Python数据框。我想使用另一个数据框中的匹配值更新第一个数据框中的行。第二个数据框作为覆盖。
这里有一个带有相同数据和代码的示例:
DataFrame 1:
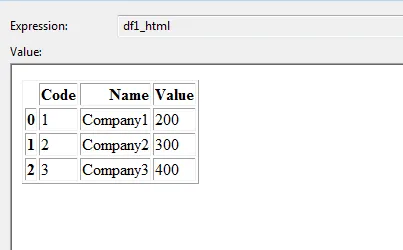
DataFrame 2:
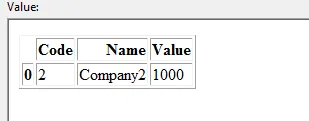
我想根据匹配的代码和名称更新数据框1。在此示例中,应将DataFrame1更新如下:
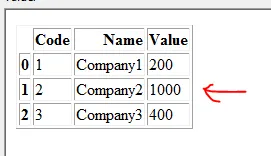
注意:具有Code =2和Name = Company2的行已更新为值1000(来自数据框2)
import pandas as pd
data1 = {
'Code': [1, 2, 3],
'Name': ['Company1', 'Company2', 'Company3'],
'Value': [200, 300, 400],
}
df1 = pd.DataFrame(data1, columns= ['Code','Name','Value'])
data2 = {
'Code': [2],
'Name': ['Company2'],
'Value': [1000],
}
df2 = pd.DataFrame(data2, columns= ['Code','Name','Value'])
有什么指导或提示吗?
Value列被转换为float类型? - AXOdf1.set_index(['Code', 'Name'], inplace=True),并且可以更新多个度量列,比如Value、Sales等。 - undefined