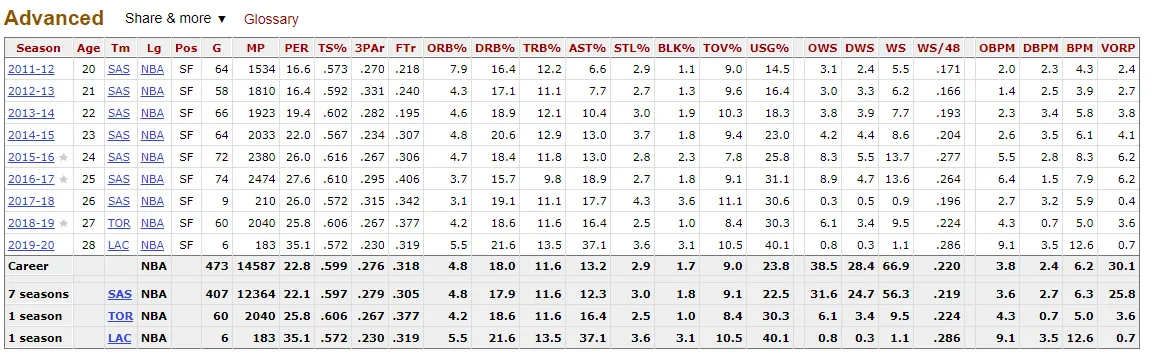
我正在尝试学习如何使用rvest包进行一些爬取。我使用这个url来加载信息,并尝试获取在URL中标记为“高级”的表格信息:
我看到的是read是一个由351个值组成的列表。好的,这意味着已检测出351个标记为正确的值。如果我获取最后一个值,read2[351],我会看到"29.3",它是第一个表格的最后一个值。
那么...我如何获取其他表格的信息呢?我从未告诉R获取第一个表格,我假设我会得到所有表格的所有信息,我的下一步将是以某种方式过滤"高级"表格的值。
问候
library(rvest)
library(stringr)
url = url("https://www.basketball-reference.com/players/l/leonaka01.html")
read = html_nodes(read_html(url),
'.right')
read2 = str_replace_all(html_text(read),
"[\r\n\t]" , "")
我看到的是read是一个由351个值组成的列表。好的,这意味着已检测出351个标记为正确的值。如果我获取最后一个值,read2[351],我会看到"29.3",它是第一个表格的最后一个值。
那么...我如何获取其他表格的信息呢?我从未告诉R获取第一个表格,我假设我会得到所有表格的所有信息,我的下一步将是以某种方式过滤"高级"表格的值。
问候