使用以下文档,我一直在试图从marketwatch.com上爬取一系列的表格。
下面的代码表示其中一个表:
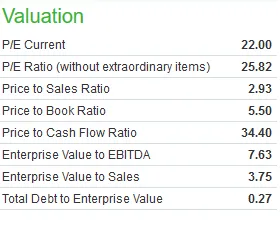
链接和xpath已经包含在代码中:
url <- "http://www.marketwatch.com/investing/stock/IRS/profile"
valuation <- url %>%
html() %>%
html_nodes(xpath='//*[@id="maincontent"]/div[2]/div[1]') %>%
html_table()
valuation <- valuation[[1]]
我遇到了以下错误:
Warning message:
'html' is deprecated.
Use 'read_html' instead.
See help("Deprecated")
提前致谢。
html()移除并替换为read_html()。 - cory