我想要找到我的数据中每一列的
NaN 数量。import numpy as np
import pandas as pd
raw_data = {'first_name': ['Jason', np.nan, 'Tina', 'Jake', 'Amy'],
'last_name': ['Miller', np.nan, np.nan, 'Milner', 'Cooze'],
'age': [22, np.nan, 23, 24, 25],
'sex': ['m', np.nan, 'f', 'm', 'f'],
'Test1_Score': [4, np.nan, 0, 0, 0],
'Test2_Score': [25, np.nan, np.nan, 0, 0]}
results = pd.DataFrame(raw_data, columns = ['first_name', 'last_name', 'age', 'sex', 'Test1_Score', 'Test2_Score'])
results
'''
first_name last_name age sex Test1_Score Test2_Score
0 Jason Miller 22.0 m 4.0 25.0
1 NaN NaN NaN NaN NaN NaN
2 Tina NaN 23.0 f 0.0 NaN
3 Jake Milner 24.0 m 0.0 0.0
4 Amy Cooze 25.0 f 0.0 0.0
'''
您可以使用以下函数,它将以Dataframe形式给出输出:
只需复制并粘贴以下函数,并通过传递您的Pandas Dataframe来调用它
def missing_zero_values_table(df):
zero_val = (df == 0.00).astype(int).sum(axis=0)
mis_val = df.isnull().sum()
mis_val_percent = 100 * df.isnull().sum() / len(df)
mz_table = pd.concat([zero_val, mis_val, mis_val_percent], axis=1)
mz_table = mz_table.rename(
columns = {0 : 'Zero Values', 1 : 'Missing Values', 2 : '% of Total Values'})
mz_table['Total Zero Missing Values'] = mz_table['Zero Values'] + mz_table['Missing Values']
mz_table['% Total Zero Missing Values'] = 100 * mz_table['Total Zero Missing Values'] / len(df)
mz_table['Data Type'] = df.dtypes
mz_table = mz_table[
mz_table.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
print ("Your selected dataframe has " + str(df.shape[1]) + " columns and " + str(df.shape[0]) + " Rows.\n"
"There are " + str(mz_table.shape[0]) +
" columns that have missing values.")
# mz_table.to_excel('D:/sampledata/missing_and_zero_values.xlsx', freeze_panes=(1,0), index = False)
return mz_table
missing_zero_values_table(results)
输出
Your selected dataframe has 6 columns and 5 Rows.
There are 6 columns that have missing values.
Zero Values Missing Values % of Total Values Total Zero Missing Values % Total Zero Missing Values Data Type
last_name 0 2 40.0 2 40.0 object
Test2_Score 2 2 40.0 4 80.0 float64
first_name 0 1 20.0 1 20.0 object
age 0 1 20.0 1 20.0 float64
sex 0 1 20.0 1 20.0 object
Test1_Score 3 1 20.0 4 80.0 float64
如果您希望简单处理,可以使用以下函数来获取缺失值的百分比。
def missing(dff):
print (round((dff.isnull().sum() * 100/ len(dff)),2).sort_values(ascending=False))
missing(results)
'''
Test2_Score 40.0
last_name 40.0
Test1_Score 20.0
sex 20.0
age 20.0
first_name 20.0
dtype: float64
'''
请按以下列数使用
dataframe.columnName.isnull().sum()
计算零的数量:
df[df == 0].count(axis=0)
计算 NaN:
df.isnull().sum()
df.isna().sum()
希望这可以帮助到您,
import pandas as pd
import numpy as np
df = pd.DataFrame({'a':[1,2,np.nan], 'b':[np.nan,1,np.nan],'c':[np.nan,2,np.nan], 'd':[np.nan,np.nan,np.nan]})
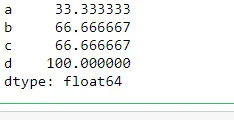
df.isnull().sum()/len(df) * 100
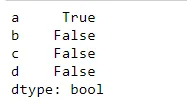
Thres = 40
(df.isnull().sum()/len(df) * 100 ) < Thres
您可以使用value_counts方法并打印np.nan的值
s.value_counts(dropna = False)[np.nan]
s.value_counts(dropna = False) - icemtel还有一个简单的选项没有提到,就是只计算NaN值的数量,可以将shape加入到代码中返回具有NaN值的行数。
df[df['col_name'].isnull()]['col_name'].shape
NaN,我们有多种方法。count ,由于 count 会忽略 NaN,这与 size 不同。print(len(df) - df.count())
方法2 使用 isnull / isna 和 sum 组合的链式方式
print(df.isnull().sum())
#print(df.isna().sum())
第三种方法 describe / info :注意这将输出 'notnull' 值的计数。
print(df.describe())
#print(df.info())
numpy的方法
print(np.count_nonzero(np.isnan(df.values),axis=0))
针对第二部分问题,在需要按照阈值来删除列时,我们可以尝试使用 dropna 函数。
thresh,可选项,需要指定非空数据的数量。
Thresh = n # no null value require, you can also get the by int(x% * len(df))
df = df.dropna(thresh = Thresh, axis = 1)
df1.isnull().sum()
这将解决问题。
这里是逐列计算 Null 值的代码:
df.isna().sum()
您可以尝试以下方法:
In [1]: s = pd.DataFrame('a'=[1,2,5, np.nan, np.nan,3],'b'=[1,3, np.nan, np.nan,3,np.nan])
In [4]: s.isna().sum()
Out[4]: out = {'a'=2, 'b'=3} # the number of NaN values for each column
In [5]: s.isna().sum().sum()
Out[6]: out = 5 #the inline sum of Out[4]
df.info()不会返回一个DataFrame,该方法只是打印信息。 - jorisdf.info()即可提供每列的数据类型和非空计数。 - Rishabh