在遍历variableA列时,我想生成一个新的列,该列是values之和,只要任一variableA或variableB中的行等于variableA当前行的值。示例数据:
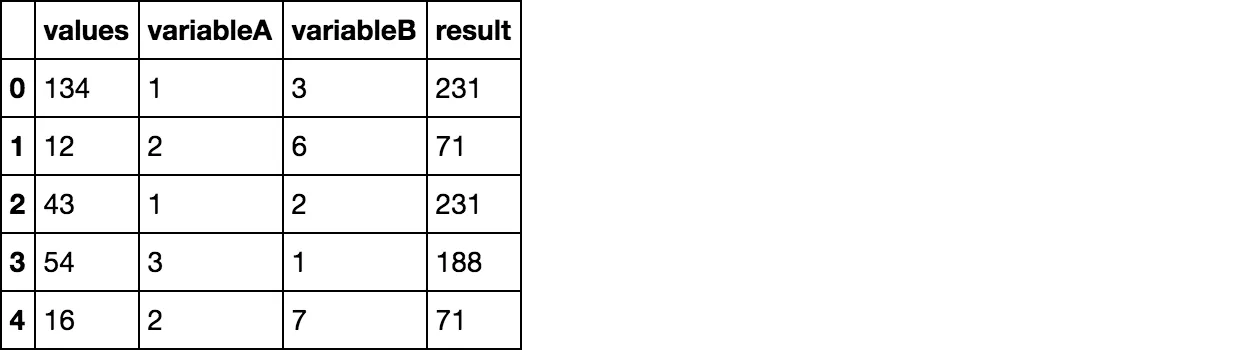
values variableA variableB
0 134 1 3
1 12 2 6
2 43 1 2
3 54 3 1
4 16 2 7
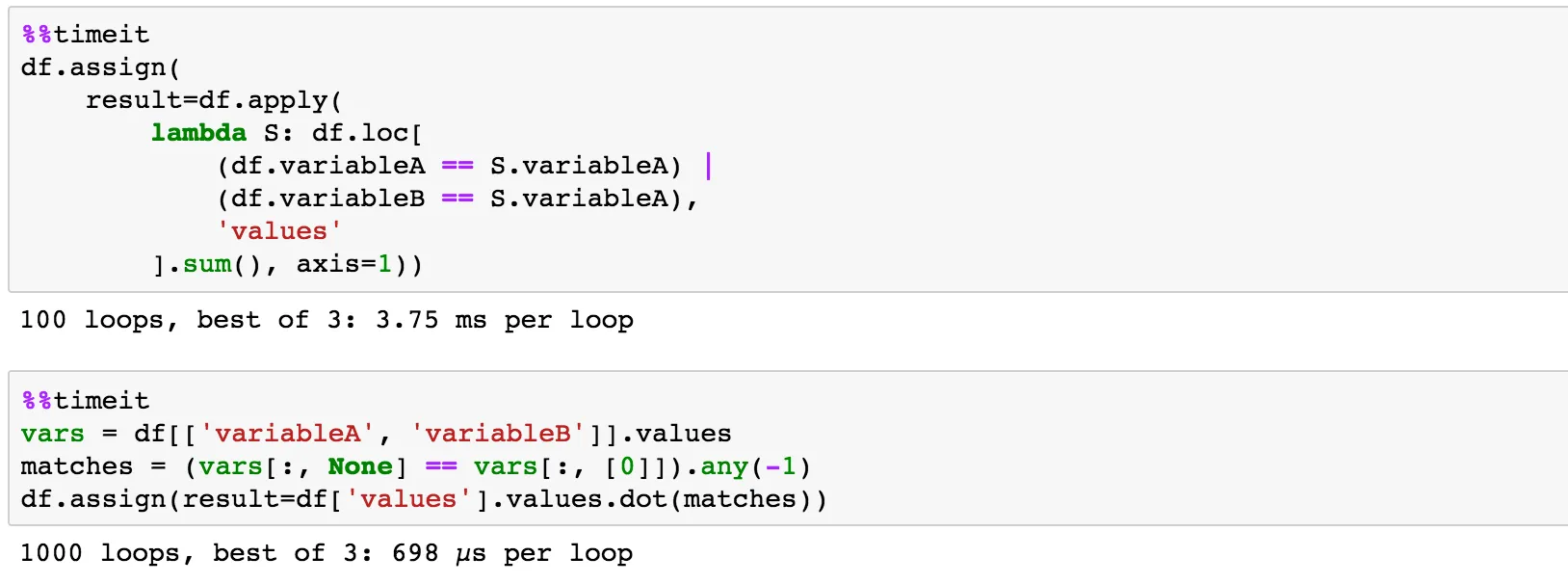
当variableA与当前行的variableA匹配时,我可以使用以下代码选择values的总和:
df.groupby('variableA')['values'].transform('sum')
但是每当variableB匹配当前行的variableA时,选择values的总和却让我感到困惑。我尝试过使用.loc,但似乎与.groupby不太兼容。期望的输出应该如下所示:
values variableA variableB result
0 134 1 3 231
1 12 2 6 71
2 43 1 2 231
3 54 3 1 188
4 16 2 7 71
谢谢!