虽然这个问题已经提出了一段时间,但为了完整起见,我提出另外两个解决方案:
d_raw <- data.frame(
course = sample(LETTERS[1:5], 500, replace = T),
nationality = as.factor(sample(1:172, 500, replace=T))
)
使用 forcats 包中的 fct_lump_n() 和 filter()
d1 <- d_raw %>%
mutate(nationality = fct_lump_n(
f = nationality,
n = 10,
ties.method = "first"
)) %>%
filter(nationality != "Other")
d1 %>% count(nationality, sort = TRUE)
ggplot(d1, aes(x = nationality, fill = course)) +
geom_bar() +
theme_classic()
fct_lump_n() 函数将除了前 10 个最常见的国籍以外的所有国籍归为类别 "Other"。请注意,在 fct_lump_n() 的参数中,需要使用 ties.method = "first" 才能确实只获取前十个国籍,而不是第 11 或 12 个国籍。即使其他国籍可能与前十个国籍同样频繁地出现,它们也都被标为 "Other"。
国籍的级别仅按字母顺序排序。
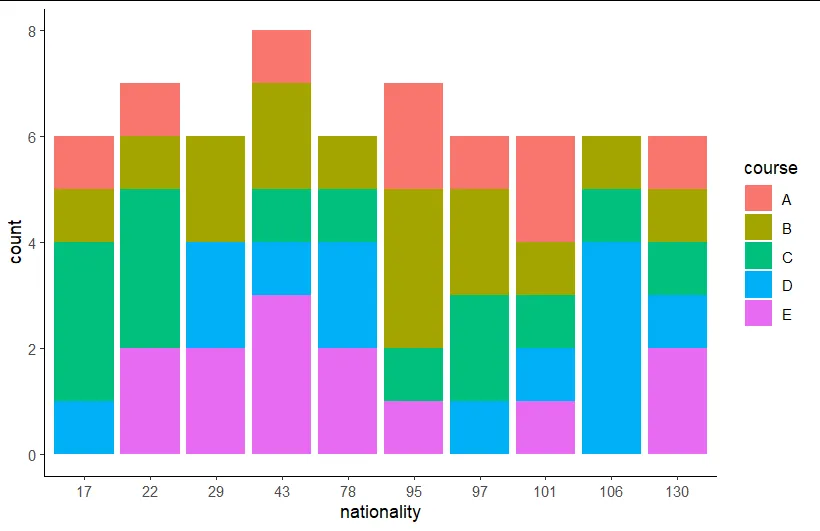
另一种解决方案是使用 forcats 包中的 fct_infreq()、cur_group_id() 和 filter()。
d2 <- d_raw %>%
group_by(nationality = fct_infreq(nationality)) %>%
filter(cur_group_id() <= 10) %>%
ungroup()
d2 %>% count(nationality, sort = TRUE)
ggplot(d2, aes(x = nationality, fill = course)) +
geom_bar() +
theme_classic()
cur_group_id() 函数为每个国籍分配一个组 ID。要从最常见的国籍开始,我们首先需要按其频率对列 nationality 进行排序。然后,我们筛选前十个组 ID 或者说最常见的国籍。
国籍的级别首先按照 n 排序,然后按字母顺序排序。
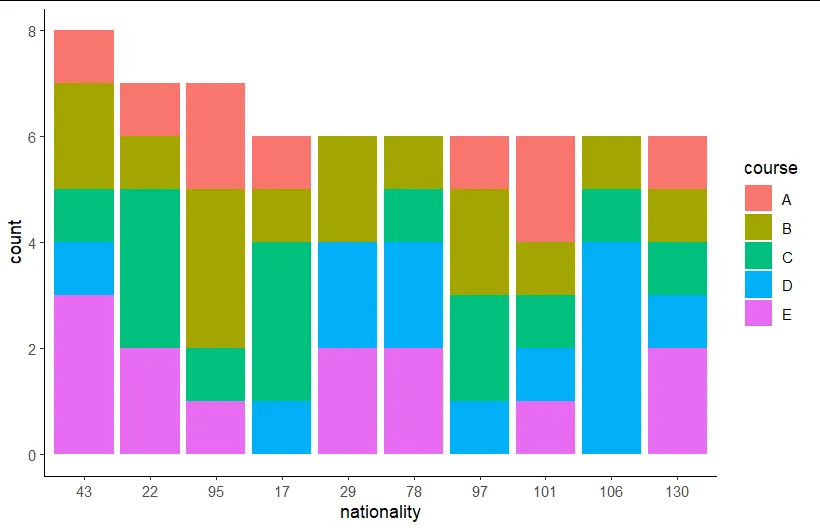
我使用 count() 来验证两个数据框 d1 和 d2 是否相同。
这两种解决方案的优点是,我们不需要第二个(临时)数据框或临时向量。
希望这能对未来的某个人有所帮助。
ggplot。这个问答,与你的情况类似,是许多例子之一。干杯。 - Henrik